Disk monitoring là một trong những hoạt động quan trọng nhất trong quản trị hệ thống, giúp phát hiện sớm các vấn đề về dung lượng, hiệu năng và độ tin cậy của ổ đĩa. Tuy nhiên, việc giám sát không đúng cách có thể dẫn đến cảnh báo giả, quá tải tài nguyên hoặc bỏ sót sự cố nghiêm trọng. Bài viết này sẽ hướng dẫn cách tối ưu disk monitoring một cách toàn diện, từ việc lựa chọn chỉ số theo dõi, thiết lập ngưỡng cảnh báo, đến tích hợp công cụ giám sát hiện đại.
Bản chất của disk monitoring và tại sao cần tối ưu
Disk monitoring là quá trình thu thập, phân tích và cảnh báo các thông số liên quan đến ổ đĩa như dung lượng trống, tốc độ đọc/ghi, độ trễ, nhiệt độ và tình trạng sức khỏe SMART. Mục tiêu chính là đảm bảo hệ thống lưu trữ hoạt động ổn định, tránh gián đoạn dịch vụ do đầy ổ cứng hoặc lỗi phần cứng.
Khi không được tối ưu, disk monitoring thường gặp các vấn đề như cảnh báo quá nhiều gây nhiễu, tiêu tốn CPU và băng thông mạng, hoặc không phát hiện kịp thời các dấu hiệu suy thoái ổ đĩa. Tối ưu hóa giúp giảm tải cho hệ thống giám sát, tăng độ chính xác của cảnh báo và tiết kiệm chi phí vận hành.
Các chỉ số quan trọng cần theo dõi trong disk monitoring
Để tối ưu disk monitoring, trước tiên cần xác định đúng các chỉ số cần giám sát. Không phải tất cả thông số đều quan trọng như nhau, và việc theo dõi quá nhiều chỉ số có thể gây quá tải.
Đây là chỉ số cơ bản nhất, đo lường phần trăm dung lượng đã sử dụng so với tổng dung lượng. Cần thiết lập ngưỡng cảnh báo ở mức 80% cho cảnh báo warning và 90% cho critical. Tuy nhiên, cần phân biệt giữa dung lượng thực tế và dung lượng dự phòng cho hệ điều hành.
Độ trễ đọc/ghi (Latency)
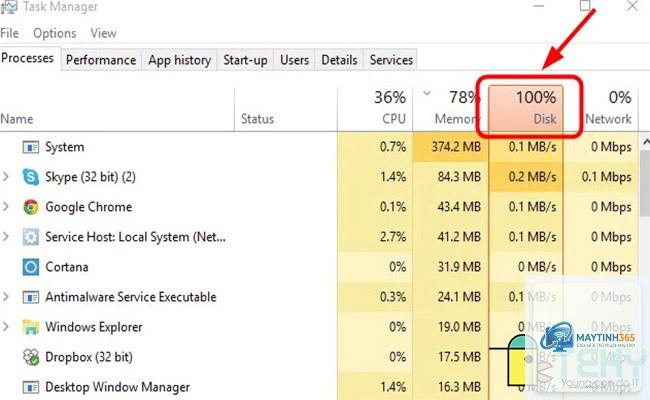
Độ trễ là thời gian phản hồi của ổ đĩa cho mỗi yêu cầu I/O. Giá trị bình thường dưới 10ms cho ổ HDD và dưới 2ms cho ổ SSD. Khi độ trễ vượt quá 20ms, cần kiểm tra ngay vì có thể là dấu hiệu của ổ đĩa sắp hỏng hoặc quá tải.
Tốc độ đọc/ghi (Throughput)
Chỉ số này đo lượng dữ liệu được đọc hoặc ghi trong một khoảng thời gian, thường tính bằng MB/s. Cần theo dõi sự thay đổi đột ngột của throughput để phát hiện các vấn đề về hiệu năng.
IOPS (Input/Output Operations Per Second)
IOPS đo số lượng thao tác I/O mỗi giây. Đây là chỉ số quan trọng cho các hệ thống database hoặc ứng dụng có tải I/O cao. Cần thiết lập baseline để phát hiện bất thường.
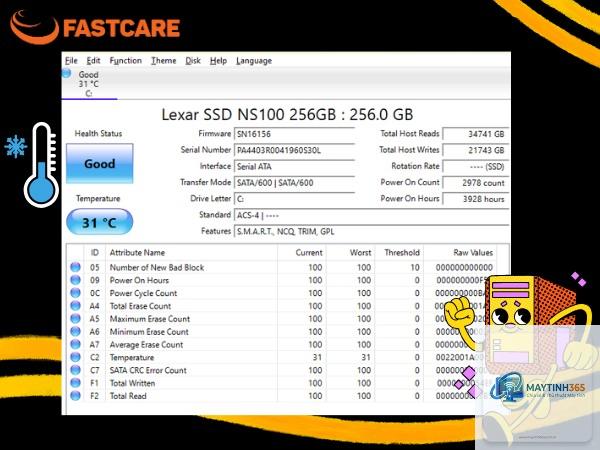
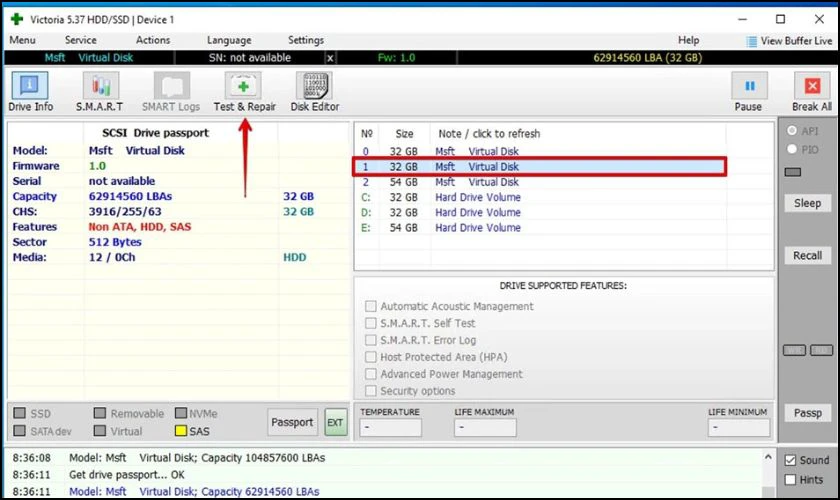
Chỉ số SMART (Self-Monitoring, Analysis, and Reporting Technology)
SMART cung cấp thông tin về sức khỏe ổ đĩa như số sector lỗi, thời gian hoạt động, nhiệt độ. Các giá trị như Reallocated Sector Count, Current Pending Sector, và Temperature cần được giám sát chặt chẽ.
Cách tối ưu disk monitoring qua thiết lập ngưỡng cảnh báo
Thiết lập ngưỡng cảnh báo là bước quan trọng nhất trong cách tối ưu disk monitoring. Một ngưỡng quá thấp sẽ gây cảnh báo giả, quá cao sẽ bỏ sót sự cố.
Nguyên tắc thiết lập ngưỡng động
Thay vì sử dụng ngưỡng cố định, nên áp dụng ngưỡng động dựa trên baseline của từng hệ thống. Ví dụ, nếu ổ đĩa thường xuyên hoạt động ở mức 70% dung lượng, ngưỡng cảnh báo nên đặt ở 85% thay vì 80% để tránh cảnh báo không cần thiết.
Phân loại mức độ cảnh báo
Mức độ
Ngưỡng dung lượng
Ngưỡng độ trễ
Hành động
Info
70%
5ms
Ghi log, không gửi cảnh báo
Warning
80%
10ms
Gửi email cho quản trị viên
Critical
90%
20ms
Gửi SMS, tạo ticket tự động
Tránh cảnh báo trùng lặp
Khi nhiều chỉ số cùng vượt ngưỡng, cần gộp cảnh báo thành một thông báo duy nhất. Ví dụ, nếu dung lượng đạt 90% và độ trễ tăng cao, chỉ gửi một cảnh báo tổng hợp thay vì hai cảnh báo riêng lẻ.
Công cụ hỗ trợ tối ưu disk monitoring
Việc lựa chọn công cụ phù hợp đóng vai trò quyết định trong cách tối ưu disk monitoring.
Prometheus và Grafana
Prometheus thu thập metrics từ node_exporter, trong đó có các chỉ số disk. Grafana trực quan hóa dữ liệu và cho phép thiết lập cảnh báo linh hoạt. Để tối ưu, cần cấu hình scrape interval phù hợp, thường là 15-30 giây cho disk monitoring.
Hai công cụ giám sát truyền thống này hỗ trợ plugin disk monitoring mạnh mẽ. Cần tối ưu bằng cách giảm tần suất kiểm tra cho các ổ đĩa ít thay đổi, chỉ tăng tần suất cho ổ đĩa quan trọng.
Datadog và New Relic
Các giải pháp SaaS này cung cấp disk monitoring tích hợp AI, tự động phát hiện bất thường. Để tối ưu chi phí, chỉ gửi metrics cho các ổ đĩa quan trọng và sử dụng sampling cho ổ đĩa phụ.
Quy trình tối ưu disk monitoring từ A đến Z
Áp dụng quy trình sau để đảm bảo disk monitoring hoạt động hiệu quả và tiết kiệm tài nguyên.
Bước 1: Đánh giá hiện trạng hệ thống
Liệt kê tất cả ổ đĩa trong hệ thống, phân loại theo mức độ quan trọng. Ví dụ, ổ đĩa chứa database có mức ưu tiên cao hơn ổ đĩa chứa log file.
Bước 2: Thiết lập baseline
Thu thập dữ liệu trong ít nhất 7 ngày để xác định giá trị trung bình của các chỉ số. Baseline này sẽ là cơ sở để thiết lập ngưỡng cảnh báo.
Bước 3: Cấu hình công cụ giám sát
Chọn công cụ phù hợp và cấu hình các tham số như tần suất thu thập, ngưỡng cảnh báo, kênh thông báo. Nên bắt đầu với ngưỡng rộng và thu hẹp dần sau 2 tuần vận hành.
Bước 4: Kiểm tra và tinh chỉnh
Sau khi triển khai, theo dõi số lượng cảnh báo trong 1 tuần. Nếu có quá nhiều cảnh báo giả, điều chỉnh ngưỡng. Nếu bỏ sót sự cố, giảm ngưỡng.
Bước 5: Tự động hóa phản hồi
Thiết lập các script tự động xử lý khi có cảnh báo, ví dụ tự động xóa file tạm khi dung lượng đạt 90%, hoặc gửi thông báo đến Slack.
Sai lầm thường gặp khi thực hiện disk monitoring
Nhiều quản trị viên mắc phải các sai lầm sau khiến disk monitoring không hiệu quả.
Chỉ theo dõi dung lượng mà bỏ qua hiệu năng
Dung lượng đầy là vấn đề dễ thấy, nhưng độ trễ cao hoặc IOPS thấp mới là nguyên nhân chính gây chậm hệ thống. Cần theo dõi cả hai nhóm chỉ số.
Thiết lập ngưỡng quá thấp
Đặt ngưỡng cảnh báo dung lượng ở mức 50% sẽ gây ra hàng trăm cảnh báo mỗi ngày, dẫn đến hiệu ứng “cảnh báo mệt mỏi” khiến quản trị viên bỏ qua cảnh báo thực sự.
Không phân biệt loại ổ đĩa
Ổ SSD và HDD có ngưỡng khác nhau. SSD có độ trễ thấp hơn nhưng nhạy cảm với số lần ghi. Cần thiết lập ngưỡng riêng cho từng loại.
Bỏ qua cảnh báo SMART
Nhiều người chỉ tập trung vào dung lượng mà quên theo dõi chỉ số SMART. Một ổ đĩa có Reallocated Sector Count tăng đột biến có thể hỏng trong vòng 24 giờ.
Lưu ý quan trọng khi tối ưu disk monitoring
Để đạt hiệu quả cao nhất, cần lưu ý các điểm sau trong quá trình tối ưu.
Luôn kiểm tra tác động của việc giám sát lên hiệu năng hệ thống. Công cụ giám sát cũng tiêu tốn tài nguyên, cần cân bằng giữa độ chi tiết và tải hệ thống.
Sử dụng tính năng aggregation để gộp metrics từ nhiều ổ đĩa giống nhau, giảm số lượng time series cần lưu trữ.
Thiết lập retention policy hợp lý. Dữ liệu chi tiết chỉ cần lưu 7-30 ngày, dữ liệu tổng hợp có thể lưu đến 1 năm.
Tích hợp disk monitoring với hệ thống ticketing để tự động tạo ticket khi có sự cố, giúp quy trình xử lý nhanh hơn.
Thường xuyên review và cập nhật baseline, ít nhất mỗi quý một lần, vì workload của hệ thống thay đổi theo thời gian.
Một công ty thương mại điện tử với 50 server đã áp dụng cách tối ưu disk monitoring và đạt được kết quả ấn tượng. Trước khi tối ưu, họ nhận trung bình 200 cảnh báo mỗi ngày, trong đó 80% là cảnh báo giả. Sau khi thiết lập baseline và ngưỡng động, số cảnh báo giảm xuống còn 15 cảnh báo mỗi ngày, tiết kiệm 10 giờ làm việc của đội ngũ vận hành mỗi tuần.
Một trường hợp khác, một ngân hàng đã phát hiện sớm ổ đĩa sắp hỏng nhờ theo dõi chỉ số SMART. Họ kịp thời sao lưu dữ liệu và thay thế ổ đĩa trước khi xảy ra mất dữ liệu, tránh thiệt hại ước tính 500.000 USD.
Câu hỏi thường gặp về cách tối ưu disk monitoring
Tần suất thu thập dữ liệu disk monitoring bao nhiêu là hợp lý?
Tần suất phụ thuộc vào loại ổ đĩa và mức độ quan trọng. Với ổ đĩa chứa database, nên thu thập mỗi 15-30 giây. Với ổ đĩa lưu trữ file, mỗi 5-10 phút là đủ. Không nên thu thập dưới 10 giây vì sẽ gây quá tải cho hệ thống.
Có cần giám sát tất cả ổ đĩa trong hệ thống không?
Không. Chỉ giám sát các ổ đĩa có dữ liệu quan trọng hoặc ảnh hưởng đến hiệu năng hệ thống. Các ổ đĩa tạm thời hoặc ổ đĩa dự phòng có thể bỏ qua hoặc giám sát với tần suất thấp.
Làm thế nào để phân biệt cảnh báo thật và cảnh báo giả?
Thiết lập baseline và sử dụng ngưỡng động. Nếu một chỉ số vượt ngưỡng nhưng quay lại bình thường trong vòng 5 phút, đó có thể là cảnh báo giả. Cần cấu hình thời gian duy trì cảnh báo (evaluation period) ít nhất 2-3 chu kỳ thu thập trước khi gửi cảnh báo.
Công cụ disk monitoring nào miễn phí và hiệu quả?
Prometheus kết hợp với Grafana là giải pháp miễn phí mạnh mẽ nhất. Ngoài ra, Zabbix và Nagios cũng là các lựa chọn tốt với cộng đồng hỗ trợ lớn. Các công cụ này đều hỗ trợ disk monitoring đầy đủ tính năng.
Có nên sử dụng AI trong disk monitoring không?
Có, nếu hệ thống có quy mô lớn. AI giúp tự động phát hiện bất thường và dự đoán thời điểm ổ đĩa đầy hoặc hỏng. Tuy nhiên, với hệ thống nhỏ dưới 20 server, việc thiết lập ngưỡng thủ công vẫn hiệu quả và tiết kiệm chi phí.
Kết luận
Cách tối ưu disk monitoring không chỉ đơn thuần là cài đặt một công cụ giám sát, mà là cả một quy trình từ đánh giá hiện trạng, thiết lập baseline, lựa chọn chỉ số phù hợp, đến tinh chỉnh ngưỡng cảnh báo. Việc áp dụng đúng phương pháp giúp giảm thiểu cảnh báo giả, phát hiện sớm sự cố, tiết kiệm tài nguyên và chi phí vận hành.
Bắt đầu bằng việc đánh giá hệ thống hiện tại, xác định các ổ đĩa quan trọng, và thiết lập baseline trong ít nhất một tuần. Sau đó, áp dụng các nguyên tắc về ngưỡng động, phân loại cảnh báo, và tự động hóa phản hồi. Với cách tiếp cận có hệ thống, disk monitoring sẽ trở thành công cụ đắc lực bảo vệ hệ thống thay vì là gánh nặng cho đội ngũ vận hành.