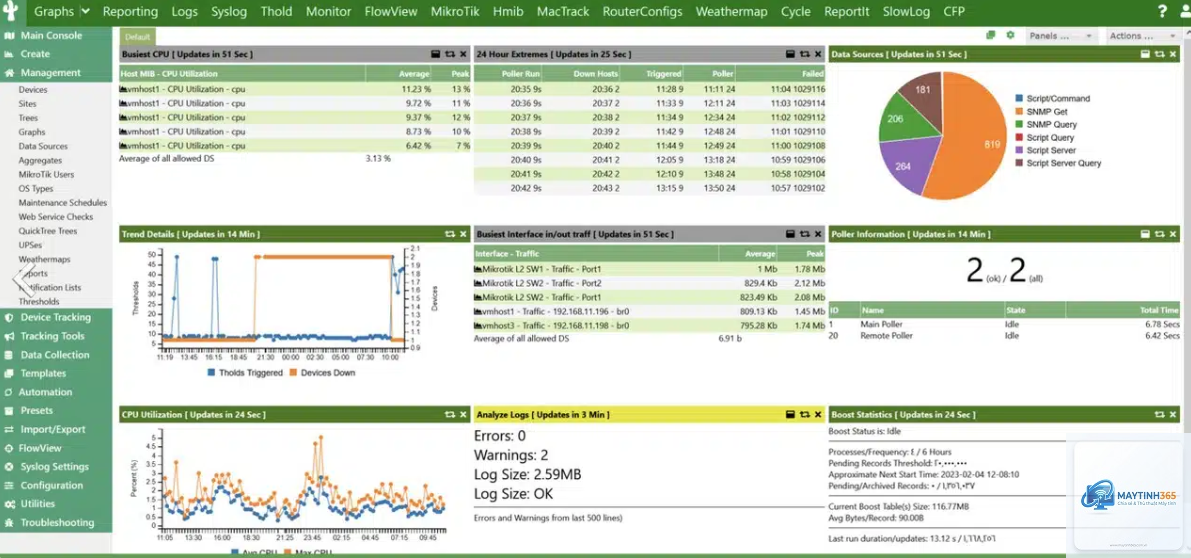
Trong bối cảnh hạ tầng mạng ngày càng phức tạp với sự bùng nổ của IoT, điện toán đám mây và làm việc từ xa, việc giám sát mạng (network monitoring) không chỉ dừng lại ở việc kiểm tra xem thiết bị có hoạt động hay không. Cách tối ưu network monitoring đòi hỏi một chiến lược tổng thể, kết hợp công nghệ, quy trình và con người để đảm bảo hiệu suất, bảo mật và tính sẵn sàng của hệ thống. Bài viết này sẽ cung cấp cho bạn một lộ trình chi tiết, từ việc hiểu đúng bản chất cho đến triển khai các giải pháp tiên tiến nhất.
Bản chất của network monitoring và tầm quan trọng của việc tối ưu
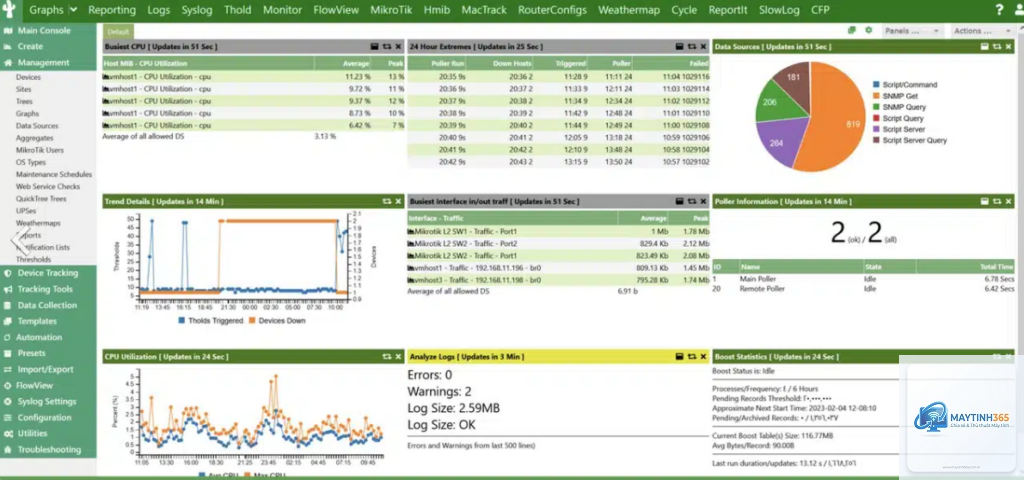
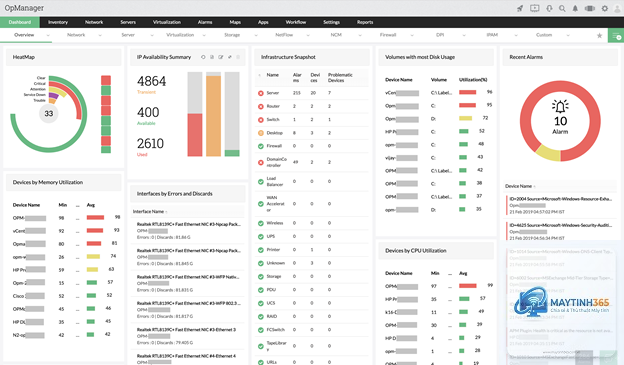
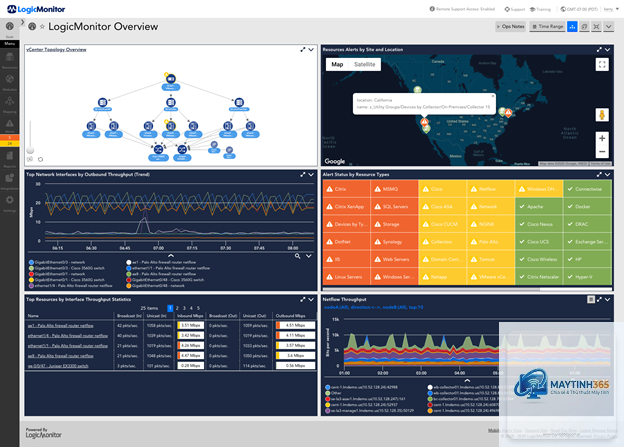
Network monitoring là quá trình liên tục theo dõi, thu thập và phân tích dữ liệu từ các thiết bị mạng như router, switch, firewall, server và các ứng dụng. Mục tiêu cuối cùng là phát hiện sớm các bất thường, sự cố tiềm ẩn và tối ưu hiệu năng trước khi chúng ảnh hưởng đến người dùng cuối. Tuy nhiên, một hệ thống monitoring không được tối ưu sẽ tạo ra lượng dữ liệu khổng lồ, dẫn đến nhiễu thông tin, cảnh báo giả và lãng phí tài nguyên.
Việc tối ưu network monitoring mang lại ba lợi ích cốt lõi. Thứ nhất, giảm thời gian phát hiện và xử lý sự cố (MTTR – Mean Time to Resolve). Thứ hai, tiết kiệm chi phí vận hành nhờ giảm tải cho hệ thống lưu trữ và xử lý. Thứ ba, nâng cao độ chính xác của cảnh báo, giúp đội ngũ vận hành tập trung vào các vấn đề thực sự quan trọng.
Các thành phần cốt lõi trong một hệ thống network monitoring hiệu quả
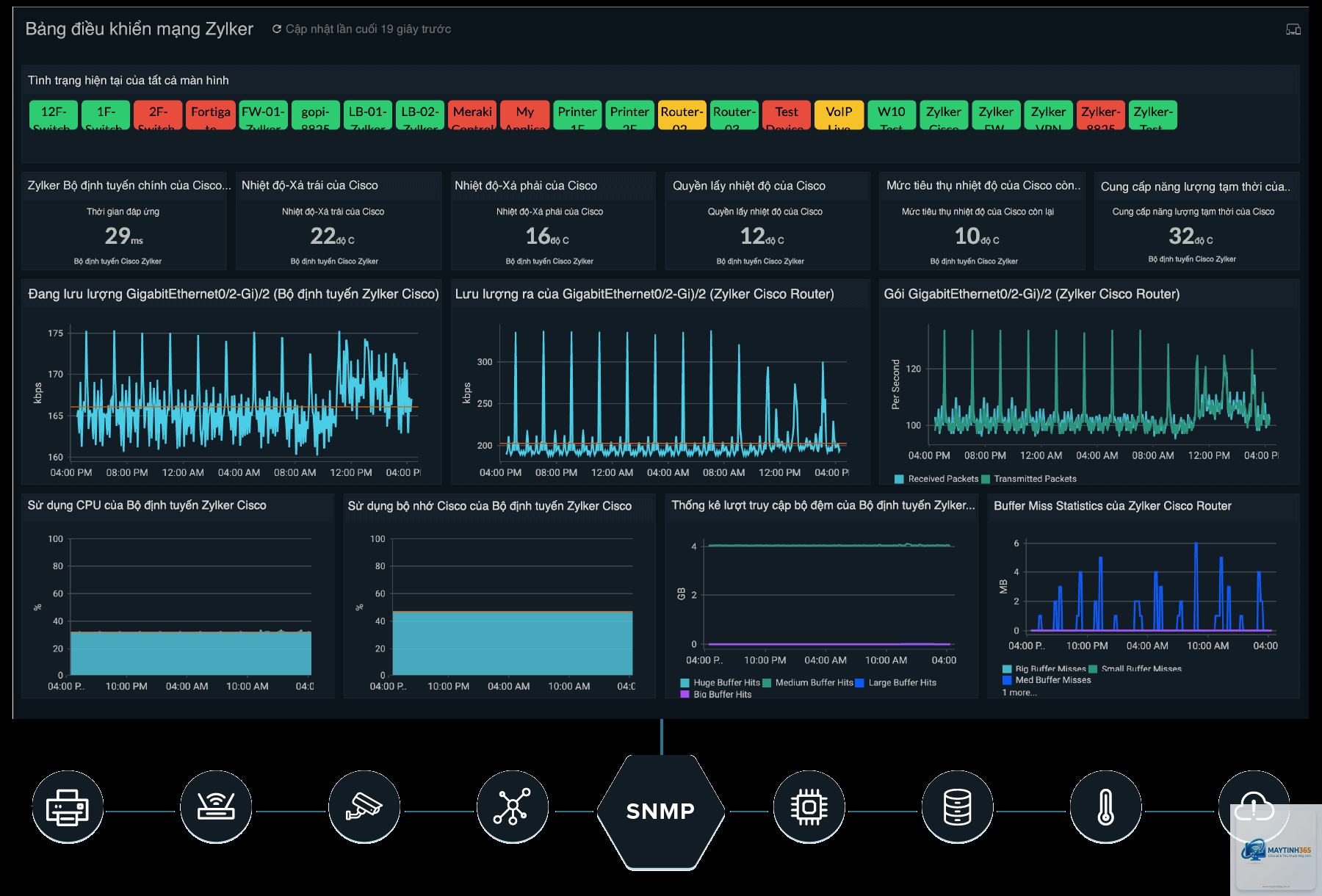
Giao thức thu thập dữ liệu: SNMP, NetFlow, sFlow và IPFIX
SNMP (Simple Network Management Protocol) là giao thức phổ biến nhất để thu thập thông tin trạng thái thiết bị như CPU, bộ nhớ, nhiệt độ. Tuy nhiên, SNMP chỉ cho biết “thiết bị đang thế nào”, không cho biết “lưu lượng đang đi đâu”. Để có cái nhìn sâu hơn, bạn cần NetFlow (Cisco), sFlow (phân tán) hoặc IPFIX (chuẩn mở).
Khi tối ưu network monitoring, việc lựa chọn giao thức phù hợp với quy mô mạng là rất quan trọng. Với mạng doanh nghiệp nhỏ, SNMP kết hợp với syslog là đủ. Với mạng lớn có hàng nghìn thiết bị, NetFlow hoặc sFlow giúp phân tích lưu lượng chi tiết mà không làm quá tải bộ xử lý của thiết bị mạng.
Nền tảng giám sát: Từ mã nguồn mở đến thương mại
Thị trường hiện có nhiều lựa chọn cho nền tảng network monitoring. Các giải pháp mã nguồn mở như Zabbix, Nagios, Prometheus phù hợp với doanh nghiệp có đội ngũ kỹ thuật mạnh, muốn tùy biến sâu. Trong khi đó, các giải pháp thương mại như SolarWinds, PRTG, Datadog cung cấp giao diện thân thiện, tích hợp sẵn nhiều tính năng và hỗ trợ kỹ thuật chuyên nghiệp.
Một nghiên cứu từ Gartner cho thấy các doanh nghiệp sử dụng giải pháp thương mại có tỷ lệ phát hiện sự cố trước khi ảnh hưởng đến người dùng cao hơn 40% so với nhóm sử dụng mã nguồn mở không được tối ưu. Tuy nhiên, chi phí bản quyền có thể là rào cản lớn với doanh nghiệp vừa và nhỏ.
Chiến lược tối ưu network monitoring theo từng lớp
Tối ưu lớp thu thập dữ liệu
Bước đầu tiên trong cách tối ưu network monitoring là giảm tải cho hệ thống thu thập. Thay vì poll tất cả thiết bị mỗi 30 giây, hãy phân loại thiết bị theo mức độ quan trọng. Thiết bị core switch, firewall, server quan trọng nên được poll mỗi 30-60 giây. Thiết bị access switch, máy in, thiết bị IoT có thể poll mỗi 5-10 phút.
Sử dụng kỹ thuật SNMP v3 với xác thực và mã hóa để đảm bảo an toàn dữ liệu. Đồng thời, thiết lập threshold thông minh dựa trên baseline (đường cơ sở) thay vì threshold tĩnh. Ví dụ, thay vì cảnh báo khi CPU vượt 90%, hãy cảnh báo khi CPU tăng đột biến 30% so với mức trung bình 7 ngày gần nhất.
Tối ưu lớp lưu trữ và xử lý
Dữ liệu monitoring có thể lên đến hàng terabyte mỗi ngày. Để tối ưu, bạn cần chiến lược lưu trữ phân tầng. Dữ liệu raw (thô) chỉ giữ 7-30 ngày trên ổ SSD tốc độ cao. Dữ liệu đã tổng hợp (aggregated) giữ 6-12 tháng trên ổ HDD. Dữ liệu lịch sử trên 12 tháng nên được nén và lưu trữ trên cloud storage với chi phí thấp.
Sử dụng cơ sở dữ liệu time-series như InfluxDB, TimescaleDB thay vì MySQL hay PostgreSQL truyền thống. Các cơ sở dữ liệu này được tối ưu cho việc ghi và truy vấn dữ liệu theo thời gian, giúp tăng tốc độ xử lý lên 5-10 lần.
Tối ưu lớp cảnh báo và thông báo
Một trong những vấn đề lớn nhất của network monitoring là “alert fatigue” (mệt mỏi vì cảnh báo). Khi có quá nhiều cảnh báo, đội ngũ vận hành sẽ bỏ qua hoặc xóa chúng mà không kiểm tra. Cách tối ưu network monitoring ở lớp này là triển khai hệ thống cảnh báo thông minh với các kỹ thuật sau:
Deduplication: Gộp các cảnh báo trùng lặp từ cùng một nguyên nhân gốc.
Correlation: Liên kết các cảnh báo khác nhau để xác định nguyên nhân gốc (root cause).
Escalation: Thiết lập quy trình leo thang theo thời gian và mức độ nghiêm trọng.
Maintenance window: Tạm dừng cảnh báo trong thời gian bảo trì định kỳ.
Ứng dụng AI và Machine Learning trong tối ưu network monitoring
Phát hiện bất thường dựa trên hành vi
Các hệ thống monitoring truyền thống chỉ phát hiện được các sự cố đã được định nghĩa trước. Với AI/ML, hệ thống có thể học hành vi bình thường của mạng và tự động phát hiện các bất thường. Ví dụ, nếu lưu lượng từ một máy chủ web đột nhiên tăng gấp 10 lần vào lúc 2 giờ sáng, hệ thống AI sẽ cảnh báo ngay lập tức, trong khi hệ thống cũ có thể bỏ qua nếu threshold chưa được cập nhật.
Kết hợp network monitoring với SOAR (Security Orchestration, Automation and Response) cho phép tự động hóa các phản hồi. Khi phát hiện một cổng switch bị lỗi, hệ thống có thể tự động chuyển lưu lượng sang cổng dự phòng, gửi ticket đến đội ngũ hỗ trợ và cập nhật trạng thái trên dashboard. Điều này giảm MTTR từ vài giờ xuống còn vài phút.
So sánh các phương pháp tối ưu network monitoring phổ biến
Phương pháp
Ưu điểm
Nhược điểm
Phù hợp với
Giảm tần suất polling
Giảm tải CPU thiết bị, giảm băng thông mạng
Mất dữ liệu chi tiết, chậm phát hiện sự cố
Mạng nhỏ, thiết bị cấu hình thấp
Sử dụng agent thay vì SNMP
Thu thập dữ liệu chi tiết hơn, ít ảnh hưởng đến thiết bị mạng
Tốn tài nguyên trên máy chủ, khó triển khai trên thiết bị mạng
Server, ứng dụng, máy ảo
Streaming telemetry
Dữ liệu real-time, ít độ trễ, giảm tải cho thiết bị
Yêu cầu thiết bị hỗ trợ, phức tạp khi triển khai
Mạng lớn, thiết bị hiện đại (Cisco IOS XE, Juniper Junos)
AI-driven monitoring
Phát hiện bất thường chính xác, giảm cảnh báo giả
Chi phí cao, cần dữ liệu huấn luyện ban đầu
Doanh nghiệp lớn, môi trường phức tạp
Các sai lầm thường gặp khi tối ưu network monitoring và cách tránh
Thu thập quá nhiều dữ liệu không cần thiết
Nhiều quản trị viên có tâm lý “càng nhiều dữ liệu càng tốt”. Họ bật tất cả các OID SNMP, thu thập mọi luồng NetFlow và lưu trữ tất cả log. Kết quả là hệ thống nhanh chóng bị quá tải, chi phí lưu trữ tăng vọt và việc tìm kiếm thông tin hữu ích trở nên khó khăn. Giải pháp là xác định rõ KPI (Key Performance Indicator) cho từng nhóm thiết bị và chỉ thu thập dữ liệu liên quan.
Không thiết lập baseline
Nếu không có baseline, bạn không thể biết được đâu là hành vi bình thường của mạng. Một mức sử dụng CPU 70% có thể là bình thường vào giờ cao điểm nhưng lại là bất thường vào lúc nửa đêm. Hãy dành ít nhất 2-4 tuần để thu thập dữ liệu baseline trước khi thiết lập các ngưỡng cảnh báo.
Bỏ qua bảo mật cho hệ thống monitoring
Hệ thống network monitoring thường có quyền truy cập rộng vào toàn bộ hạ tầng mạng. Nếu không được bảo vệ đúng cách, nó trở thành mục tiêu tấn công hấp dẫn. Sử dụng xác thực đa yếu tố, mã hóa dữ liệu truyền tải và phân quyền truy cập dựa trên vai trò (RBAC) là những biện pháp bắt buộc.
Hướng dẫn triển khai cách tối ưu network monitoring từng bước
Bước 1: Kiểm kê và phân loại tài sản mạng
Trước khi tối ưu, bạn cần biết mình đang giám sát những gì. Sử dụng công cụ discovery tự động để quét toàn bộ mạng, sau đó phân loại thiết bị theo chức năng (core, distribution, access), theo mức độ quan trọng (critical, important, normal) và theo nhà sản xuất.
Bước 2: Thiết lập baseline và KPI
Xác định các KPI chính cho từng loại thiết bị. Với router và switch, KPI bao gồm: CPU utilization, memory utilization, interface errors, packet drops, latency. Với firewall: concurrent connections, throughput, rule hits. Với server: CPU, RAM, disk I/O, network I/O.
Thu thập dữ liệu trong 2 tuần để xây dựng baseline. Sử dụng các công cụ thống kê để tính toán giá trị trung bình, độ lệch chuẩn và các ngưỡng động.
Bước 3: Tối ưu cấu hình thu thập
Điều chỉnh tần suất polling dựa trên phân loại thiết bị. Thiết lập SNMP community string an toàn (tránh dùng “public”). Cấu hình NetFlow với sampling rate phù hợp (1:100 cho mạng lớn, 1:10 cho mạng nhỏ). Kích hoạt syslog với mức độ log phù hợp (không log debug trên thiết bị sản xuất).
Bước 4: Xây dựng dashboard và cảnh báo thông minh
Tạo các dashboard theo từng nhóm đối tượng: dashboard cho đội vận hành (hiển thị trạng thái real-time), dashboard cho quản lý (hiển thị SLA và xu hướng), dashboard cho bảo mật (hiển thị các sự kiện bất thường). Thiết lập cảnh báo với các mức độ: thông tin (info), cảnh báo (warning), nghiêm trọng (critical).
Bước 5: Đánh giá và cải tiến liên tục
Hàng tháng, xem xét lại hiệu quả của hệ thống monitoring. Số lượng cảnh báo giảm bao nhiêu phần trăm? Tỷ lệ cảnh báo thật so với cảnh báo giả? Thời gian phát hiện sự cố trung bình? Dựa trên số liệu này để điều chỉnh threshold, thêm hoặc bớt các chỉ số theo dõi.
Lưu ý quan trọng khi tối ưu network monitoring
Không nên thay đổi quá nhiều tham số cùng một lúc. Mỗi lần chỉ nên điều chỉnh một hoặc hai thông số, sau đó theo dõi tác động trong ít nhất 24 giờ. Việc thay đổi đồng loạt có thể gây ra hiệu ứng domino, làm mất hoàn toàn khả năng giám sát.
Luôn có kế hoạch dự phòng cho chính hệ thống monitoring. Nếu hệ thống monitoring bị sập, bạn sẽ không biết mạng đang hoạt động ra sao. Triển khai monitoring ở chế độ high-availability với ít nhất hai máy chủ, hoặc sử dụng giải pháp monitoring-as-a-service từ bên thứ ba.
Đào tạo đội ngũ vận hành là yếu tố then chốt. Một hệ thống monitoring được tối ưu đến đâu cũng vô dụng nếu người vận hành không biết cách đọc và phản hồi dữ liệu. Tổ chức các buổi đào tạo định kỳ, xây dựng tài liệu hướng dẫn và quy trình xử lý sự cố chuẩn hóa.
Câu hỏi thường gặp về cách tối ưu network monitoring
Làm thế nào để giảm cảnh báo giả trong network monitoring?
Giảm cảnh báo giả bằng cách sử dụng threshold động dựa trên baseline thay vì threshold tĩnh. Thiết lập thời gian trễ (debounce) trước khi kích hoạt cảnh báo để tránh các đỉnh nhất thời. Sử dụng kỹ thuật correlation để gộp các cảnh báo từ cùng một nguyên nhân gốc. Cuối cùng, thường xuyên xem xét và điều chỉnh các ngưỡng cảnh báo dựa trên dữ liệu thực tế.
Có nên sử dụng một công cụ duy nhất cho toàn bộ network monitoring?
Không nên. Mỗi công cụ có thế mạnh riêng. Một chiến lược tốt là sử dụng một nền tảng chính (ví dụ Zabbix hoặc PRTG) để giám sát tổng thể, kết hợp với các công cụ chuyên biệt cho từng lĩnh vực: Wireshark cho phân tích gói tin, Elastic Stack cho quản lý log, Prometheus cho giám sát container. Điều quan trọng là các công cụ này phải tích hợp được với nhau thông qua API hoặc webhook.
Chi phí cho việc tối ưu network monitoring có đáng đầu tư không?
Chi phí cho việc tối ưu thường chỉ bằng 10-20% chi phí cho một giờ downtime của hệ thống. Với doanh nghiệp thương mại điện tử, mỗi phút downtime có thể gây thiệt hại hàng nghìn đô la. Đầu tư vào tối ưu network monitoring giúp giảm thời gian downtime, tăng năng suất đội ngũ vận hành và kéo dài tuổi thọ thiết bị mạng. Đây là khoản đầu tư có ROI rất cao.
Kết luận
Cách tối ưu network monitoring không phải là một đích đến mà là một hành trình liên tục. Bắt đầu từ việc hiểu rõ hạ tầng mạng, thiết lập baseline, lựa chọn công cụ phù hợp và không ngừng cải tiến dựa trên dữ liệu thực tế. Các công nghệ như AI, machine learning và tự động hóa đang mở ra những khả năng mới, giúp việc giám sát mạng trở nên thông minh và hiệu quả hơn bao giờ hết.
Điều quan trọng nhất là xây dựng một văn hóa vận hành chủ động, nơi mà việc giám sát không chỉ là trách nhiệm của một cá nhân hay một phòng ban, mà là một phần trong chiến lược vận hành tổng thể của doanh nghiệp. Với một hệ thống network monitoring được tối ưu đúng cách, bạn không chỉ phát hiện sự cố nhanh hơn mà còn có thể dự đoán và ngăn chặn chúng trước khi xảy ra.