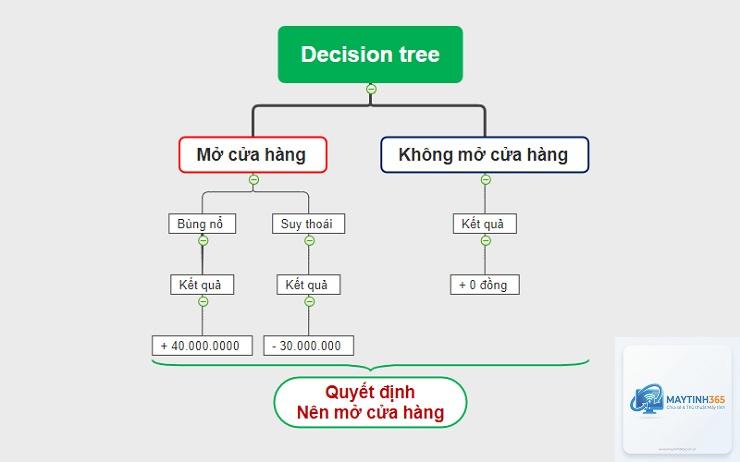
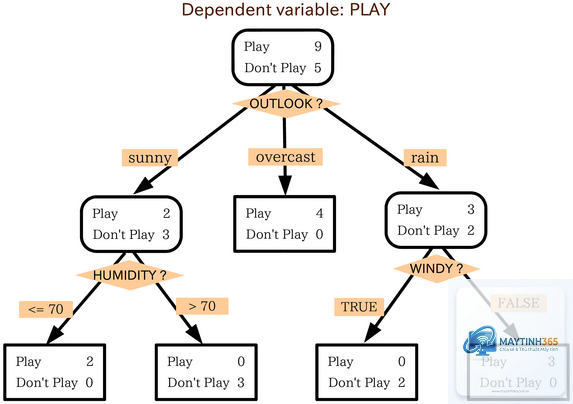
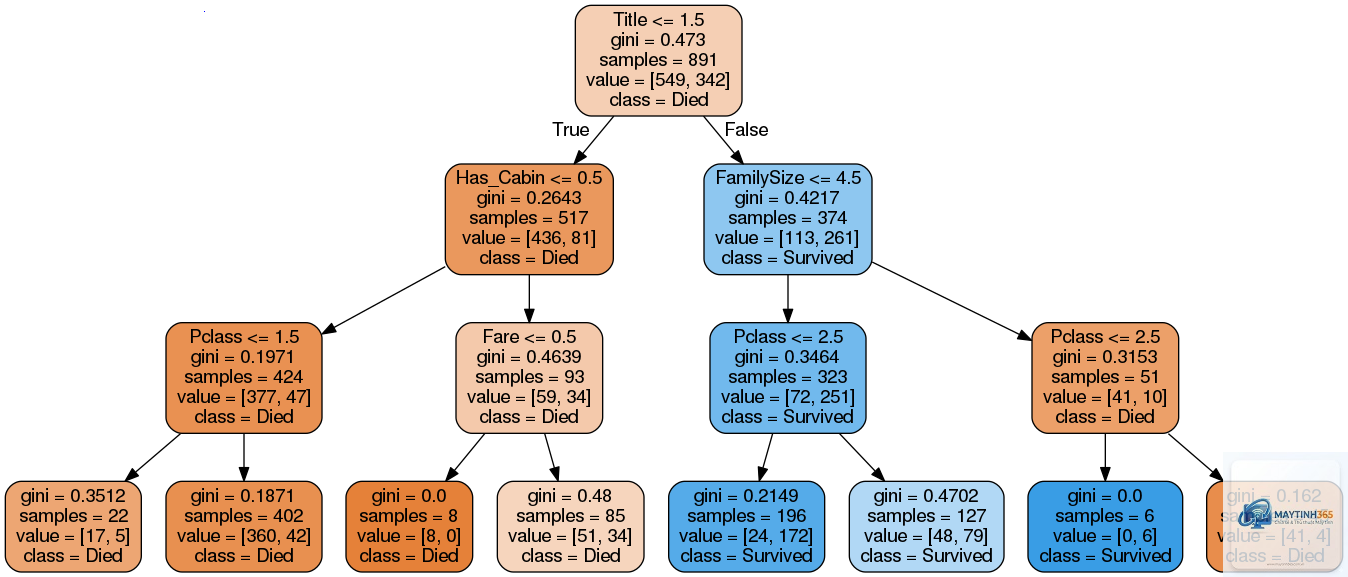
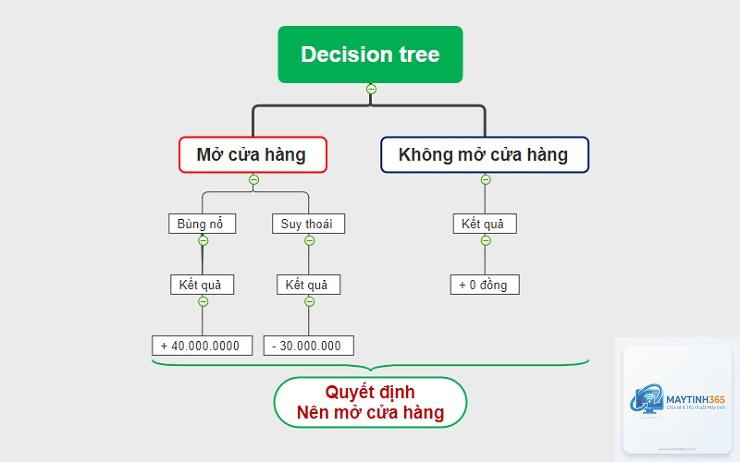
Trong thế giới dữ liệu ngày nay, việc đưa ra quyết định dựa trên thông tin là yếu tố sống còn. Decision Tree (Cây quyết định) nổi lên như một công cụ mạnh mẽ giúp con người và máy móc đưa ra lựa chọn một cách có hệ thống. Decision Tree là gì? Đây là một mô hình học máy có giám sát, sử dụng cấu trúc dạng cây để biểu diễn các quyết định và hậu quả của chúng. Mô hình này hoạt động bằng cách chia nhỏ một tập dữ liệu phức tạp thành các nhánh nhỏ hơn dựa trên các câu hỏi “nếu-thì”, cho đến khi đạt được kết luận cuối cùng. Decision Tree được ứng dụng rộng rãi trong phân loại, hồi quy và khai thác dữ liệu nhờ tính trực quan và dễ giải thích.
Decision Tree mô phỏng cách con người đưa ra quyết định: đặt câu hỏi, phân tích các lựa chọn và chọn hướng đi tốt nhất. Cấu trúc của một Decision Tree bao gồm ba thành phần chính: nút gốc, nút quyết định và nút lá. Mỗi nút đại diện cho một thuộc tính hoặc một câu hỏi, mỗi nhánh là một câu trả lời, và mỗi nút lá là kết quả cuối cùng.
Nút gốc (Root Node)
Đây là điểm bắt đầu của toàn bộ cây, chứa toàn bộ tập dữ liệu. Nút gốc thường được chọn dựa trên thuộc tính có khả năng phân chia dữ liệu tốt nhất, sử dụng các chỉ số như Gini Impurity hoặc Information Gain. Ví dụ, trong bài toán dự đoán khả năng mua hàng, nút gốc có thể là “Thu nhập hàng tháng”.
Nút quyết định (Decision Node)
Các nút này xuất hiện ở các nhánh bên trong, đại diện cho các câu hỏi trung gian. Mỗi nút quyết định tiếp tục chia nhỏ dữ liệu thành các tập con dựa trên một thuộc tính khác. Quá trình này lặp lại cho đến khi không thể chia nhỏ hơn hoặc đạt được tiêu chí dừng.
Nút lá (Leaf Node)
Nút lá là điểm kết thúc của mỗi nhánh, chứa nhãn hoặc giá trị dự đoán cuối cùng. Trong bài toán phân loại, nút lá là lớp dự đoán. Trong bài toán hồi quy, nút lá là giá trị số trung bình của các mẫu trong nhánh đó.
Decision Tree hoạt động dựa trên nguyên lý chia để trị. Mô hình bắt đầu từ nút gốc, đặt câu hỏi về một thuộc tính, và dựa trên câu trả lời, dữ liệu được chuyển xuống nhánh tương ứng. Quá trình này tiếp tục cho đến khi đạt đến nút lá. Để xác định thuộc tính nào được chọn để phân chia tại mỗi nút, Decision Tree sử dụng các thuật toán tối ưu.
Thuật toán xây dựng Decision Tree
Có ba thuật toán phổ biến để xây dựng Decision Tree: ID3, C4.5 và CART. Mỗi thuật toán sử dụng một tiêu chí khác nhau để chọn thuộc tính phân chia.
Thuật toán
Tiêu chí phân chia
Đặc điểm chính
ID3
Information Gain (Gain thông tin)
Chỉ xử lý dữ liệu rời rạc, dễ bị overfitting
C4.5
Gain Ratio (Tỷ lệ lợi ích)
Cải tiến từ ID3, xử lý được dữ liệu liên tục và missing values
CART
Gini Impurity (Độ tạp chất Gini)
Hỗ trợ cả phân loại và hồi quy, tạo cây nhị phân
Information Gain và Gini Impurity
Information Gain đo lường mức độ giảm entropy (độ hỗn loạn) sau khi phân chia dữ liệu. Thuộc tính nào mang lại Information Gain cao nhất sẽ được chọn làm nút phân chia. Gini Impurity đo lường xác suất một mẫu bị phân loại sai nếu được gán nhãn ngẫu nhiên. Giá trị Gini càng thấp, độ tinh khiết của tập dữ liệu càng cao.
Phân loại Decision Tree
Decision Tree được chia thành hai loại chính dựa trên mục đích sử dụng: cây phân loại và cây hồi quy. Sự khác biệt nằm ở loại biến mục tiêu và cách tính giá trị tại nút lá.
Cây phân loại (Classification Tree)
Loại cây này dùng để dự đoán các biến mục tiêu rời rạc, ví dụ: “Có” hoặc “Không”, “Mua” hoặc “Không mua”. Tại mỗi nút lá, mô hình gán nhãn lớp chiếm đa số trong tập dữ liệu con. Cây phân loại thường được sử dụng trong chẩn đoán bệnh, phát hiện gian lận và phân khúc khách hàng.
Cây hồi quy (Regression Tree)
Khác với cây phân loại, cây hồi quy dự đoán các giá trị số liên tục như giá nhà, nhiệt độ hoặc doanh thu. Tại nút lá, giá trị dự đoán là trung bình cộng của tất cả các mẫu trong nhánh đó. Cây hồi quy thường được ứng dụng trong dự báo tài chính và phân tích chuỗi thời gian.
Lợi ích và hạn chế của Decision Tree
Decision Tree mang lại nhiều ưu điểm vượt trội nhưng cũng tồn tại những nhược điểm cần lưu ý. Hiểu rõ cả hai mặt giúp người dùng áp dụng mô hình một cách hiệu quả.
Lợi ích của Decision Tree
Tính trực quan cao: Cấu trúc dạng cây dễ hiểu, dễ giải thích ngay cả với người không chuyên về kỹ thuật.
Không yêu cầu chuẩn hóa dữ liệu: Decision Tree có thể xử lý cả dữ liệu số và dữ liệu phân loại mà không cần biến đổi.
Xử lý tốt dữ liệu phi tuyến tính: Mô hình có thể nắm bắt các mối quan hệ phức tạp giữa các thuộc tính.
Ít bị ảnh hưởng bởi outlier: Các giá trị ngoại lai không tác động mạnh đến cấu trúc tổng thể của cây.
Cho phép kiểm tra độ quan trọng của thuộc tính: Decision Tree tự động xếp hạng các thuộc tính dựa trên mức độ đóng góp vào quyết định.
Hạn chế của Decision Tree
Dễ bị overfitting: Cây quá sâu và phức tạp có thể học thuộc lòng dữ liệu huấn luyện, dẫn đến hiệu suất kém trên dữ liệu mới.
Nhạy cảm với thay đổi nhỏ trong dữ liệu: Một thay đổi nhỏ có thể làm thay đổi toàn bộ cấu trúc cây.
Thiên vị thuộc tính có nhiều giá trị: Các thuộc tính có nhiều mức giá trị thường được ưu tiên chọn làm nút phân chia.
Không phù hợp với dữ liệu có nhiều chiều: Khi số lượng thuộc tính lớn, cây trở nên phức tạp và khó quản lý.
So sánh Decision Tree với các mô hình học máy khác
Để đánh giá vị trí của Decision Tree, cần so sánh với các mô hình phổ biến khác như Random Forest, SVM và Neural Network.
Tiêu chí
Decision Tree
Random Forest
SVM
Neural Network
Độ chính xác
Trung bình
Cao
Cao
Rất cao
Khả năng giải thích
Rất tốt
Trung bình
Kém
Kém
Thời gian huấn luyện
Nhanh
Trung bình
Chậm
Rất chậm
Xử lý dữ liệu lớn
Kém
Tốt
Trung bình
Rất tốt
Khả năng chống overfitting
Kém
Tốt
Tốt
Trung bình
Ứng dụng thực tế của Decision Tree
Decision Tree được ứng dụng trong nhiều lĩnh vực khác nhau nhờ tính linh hoạt và dễ triển khai.
Trong y tế và chẩn đoán bệnh
Các bệnh viện sử dụng Decision Tree để hỗ trợ chẩn đoán dựa trên triệu chứng và kết quả xét nghiệm. Ví dụ, một cây quyết định có thể giúp xác định bệnh nhân có nguy cơ mắc tiểu đường dựa trên các yếu tố như tuổi, chỉ số BMI, đường huyết và tiền sử gia đình. Mô hình này giúp bác sĩ đưa ra quyết định nhanh chóng và chính xác hơn.
Trong tài chính và ngân hàng
Các ngân hàng áp dụng Decision Tree để đánh giá rủi ro tín dụng. Mô hình phân tích lịch sử giao dịch, thu nhập, nợ hiện tại và các yếu tố khác để quyết định có phê duyệt khoản vay hay không. Ngoài ra, Decision Tree còn được dùng để phát hiện giao dịch gian lận bằng cách xác định các mẫu bất thường trong dữ liệu giao dịch.
Trong marketing và phân khúc khách hàng
Các doanh nghiệp sử dụng Decision Tree để phân loại khách hàng dựa trên hành vi mua sắm, độ tuổi, giới tính và vị trí địa lý. Từ đó, họ có thể thiết kế chiến dịch quảng cáo cá nhân hóa, tối ưu hóa tỷ lệ chuyển đổi và tăng doanh thu.
Trong sản xuất và kiểm soát chất lượng
Decision Tree giúp xác định nguyên nhân gây lỗi sản phẩm bằng cách phân tích các thông số sản xuất như nhiệt độ, áp suất, tốc độ máy. Mô hình này cho phép nhà máy nhanh chóng xác định và khắc phục sự cố, giảm thiểu tỷ lệ phế phẩm.
Hướng dẫn xây dựng Decision Tree từng bước
Để xây dựng một Decision Tree hiệu quả, cần tuân thủ quy trình có hệ thống.
Bước 1: Thu thập và tiền xử lý dữ liệu
Dữ liệu đầu vào phải được làm sạch, loại bỏ các giá trị thiếu và xử lý outlier. Các thuộc tính phân loại cần được mã hóa thành dạng số nếu sử dụng thư viện như scikit-learn. Dữ liệu nên được chia thành tập huấn luyện (70-80%) và tập kiểm tra (20-30%).
Bước 2: Chọn thuật toán và tham số
Lựa chọn thuật toán phù hợp (ID3, C4.5 hoặc CART) dựa trên đặc điểm dữ liệu. Các tham số quan trọng cần cấu hình bao gồm độ sâu tối đa của cây (max_depth), số lượng mẫu tối thiểu để phân chia (min_samples_split) và số lượng mẫu tối thiểu tại nút lá (min_samples_leaf).
Bước 3: Huấn luyện mô hình
Sử dụng dữ liệu huấn luyện để xây dựng cây. Mô hình sẽ tự động chọn thuộc tính tốt nhất tại mỗi nút dựa trên tiêu chí đã chọn. Quá trình này tiếp tục cho đến khi đạt điều kiện dừng.
Bước 4: Đánh giá và tối ưu hóa
Sử dụng tập kiểm tra để đánh giá hiệu suất mô hình qua các chỉ số như độ chính xác (accuracy), độ chính xác (precision), độ nhạy (recall) và F1-score. Nếu mô hình bị overfitting, cần giảm độ sâu của cây hoặc áp dụng kỹ thuật pruning (tỉa cành).
Sai lầm thường gặp khi sử dụng Decision Tree
Nhiều người mới bắt đầu mắc phải những sai lầm phổ biến khi làm việc với Decision Tree. Nhận biết và tránh những lỗi này giúp cải thiện đáng kể hiệu quả mô hình.
Không giới hạn độ sâu của cây: Để cây phát triển tự do dẫn đến overfitting nghiêm trọng. Luôn đặt tham số max_depth hợp lý, thường từ 3 đến 10.
Bỏ qua việc xử lý dữ liệu mất cân bằng: Khi một lớp chiếm đa số, cây có xu hướng thiên vị lớp đó. Cần sử dụng kỹ thuật oversampling, undersampling hoặc điều chỉnh trọng số.
Không kiểm tra độ quan trọng của thuộc tính: Một số thuộc tính không mang lại giá trị thông tin nhưng vẫn được đưa vào, làm tăng độ phức tạp của cây.
Sử dụng Decision Tree cho dữ liệu có quá nhiều thuộc tính: Khi số lượng thuộc tính lớn hơn 100, cây trở nên khó đọc và kém hiệu quả. Nên kết hợp với kỹ thuật giảm chiều dữ liệu.
Lưu ý quan trọng khi triển khai Decision Tree
Để đạt được kết quả tối ưu, cần ghi nhớ một số lưu ý sau đây khi triển khai Decision Tree trong thực tế.
Luôn thực hiện pruning (tỉa cành) sau khi huấn luyện để loại bỏ các nhánh không cần thiết, giảm overfitting và cải thiện khả năng tổng quát hóa.
Sử dụng kỹ thuật cross-validation (kiểm tra chéo) để đánh giá độ ổn định của mô hình, tránh phụ thuộc vào một tập dữ liệu kiểm tra duy nhất.
Kết hợp Decision Tree với các mô hình ensemble như Random Forest hoặc Gradient Boosting để tăng độ chính xác và giảm variance.
Kiểm tra tính khả thi của mô hình trong môi trường sản xuất: Decision Tree có thể được triển khai dễ dàng dưới dạng các quy tắc if-else, phù hợp với các hệ thống nhúng.
Có, một số thuật toán như C4.5 có cơ chế xử lý giá trị thiếu bằng cách phân bổ mẫu vào tất cả các nhánh với trọng số tương ứng. Tuy nhiên, nên xử lý dữ liệu thiếu trước khi huấn luyện để đạt kết quả tốt hơn.
Làm thế nào để chọn độ sâu tối ưu cho Decision Tree?
Sử dụng kỹ thuật cross-validation kết hợp với grid search để thử nghiệm các giá trị max_depth khác nhau. Độ sâu tối ưu thường nằm trong khoảng 3 đến 10, tùy thuộc vào độ phức tạp của dữ liệu.
Decision Tree có phù hợp với dữ liệu thời gian thực không?
Có, Decision Tree có thời gian dự đoán rất nhanh (O(log n)) nên phù hợp với các ứng dụng thời gian thực như phát hiện gian lận trực tuyến hoặc hệ thống khuyến nghị.
Sự khác biệt giữa Decision Tree và Random Forest là gì?
Random Forest là tập hợp của nhiều Decision Tree, mỗi cây được huấn luyện trên một tập dữ liệu con ngẫu nhiên. Kết quả cuối cùng là trung bình hoặc biểu quyết của tất cả các cây, giúp giảm overfitting và tăng độ chính xác.
Có thể sử dụng Decision Tree cho bài toán hồi quy không?
Có, Decision Tree hồi quy (Regression Tree) được sử dụng để dự đoán các giá trị số liên tục. Tại nút lá, giá trị dự đoán là trung bình của tất cả các mẫu trong nhánh đó.
Decision Tree là một công cụ học máy mạnh mẽ, trực quan và dễ triển khai, phù hợp cho cả người mới bắt đầu và chuyên gia. Với khả năng xử lý cả dữ liệu phân loại và hồi quy, Decision Tree đã chứng minh giá trị trong nhiều lĩnh vực từ y tế, tài chính đến marketing và sản xuất. Tuy nhiên, để khai thác tối đa tiềm năng của mô hình, cần hiểu rõ cấu trúc, thuật toán xây dựng, cũng như các kỹ thuật tối ưu hóa như pruning và cross-validation. Khi kết hợp với các mô hình ensemble, Decision Tree trở thành nền tảng vững chắc cho các hệ thống trí tuệ nhân tạo hiện đại. Việc nắm vững Decision Tree không chỉ giúp giải quyết các bài toán thực tế mà còn mở ra cánh cửa để khám phá các kỹ thuật học máy nâng cao hơn.