Trong thế giới dữ liệu ngày nay, việc lựa chọn đúng loại cơ sở dữ liệu quyết định hiệu suất của toàn bộ hệ thống. Column Database, hay còn gọi là cơ sở dữ liệu cột, đã nổi lên như một giải pháp tối ưu cho các tác vụ phân tích và xử lý khối lượng dữ liệu khổng lồ. Khác với cơ sở dữ liệu quan hệ truyền thống lưu trữ theo hàng, Column Database tổ chức dữ liệu theo từng cột riêng biệt, mang lại tốc độ truy vấn vượt trội cho các hoạt động đọc và tổng hợp dữ liệu. Bài viết này sẽ đi sâu vào bản chất, kiến trúc, ưu nhược điểm và ứng dụng thực tế của Column Database, giúp bạn hiểu rõ tại sao nó trở thành lựa chọn hàng đầu trong lĩnh vực Big Data và Business Intelligence.
Bản chất của Column Database: Lưu trữ theo cột là gì?
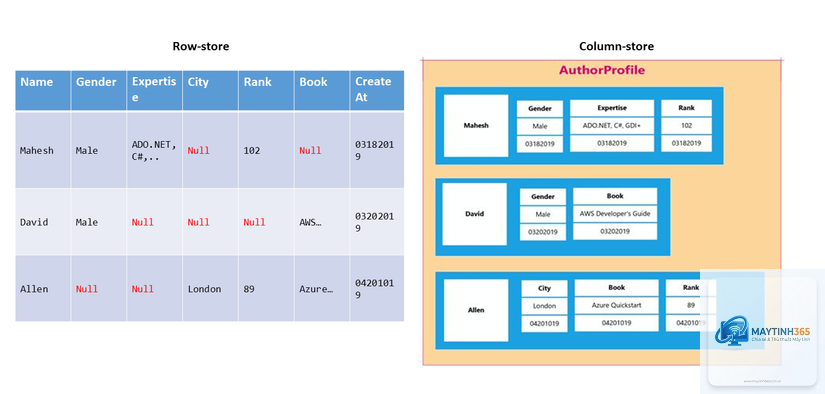
Column Database là một hệ thống quản lý cơ sở dữ liệu lưu trữ dữ liệu theo từng cột thay vì theo từng hàng như các cơ sở dữ liệu quan hệ truyền thống (ví dụ MySQL, PostgreSQL). Trong một bảng dữ liệu thông thường, mỗi hàng đại diện cho một bản ghi hoàn chỉnh. Tuy nhiên, Column Database sẽ lấy tất cả giá trị của một cột và lưu chúng liên tiếp nhau trên đĩa cứng. Điều này tạo ra sự khác biệt cơ bản trong cách dữ liệu được đọc và xử lý.
Ví dụ, với một bảng chứa thông tin khách hàng gồm các cột: ID, Tên, Tuổi, Thành phố. Cơ sở dữ liệu hàng sẽ lưu toàn bộ thông tin của khách hàng đầu tiên, sau đó đến khách hàng thứ hai. Trong khi đó, Column Database sẽ lưu tất cả ID lại với nhau, tất cả Tên lại với nhau, và cứ thế tiếp tục. Cách tổ chức này tối ưu hóa cho các truy vấn chỉ cần đọc một vài cột từ hàng triệu bản ghi.
Column Database sử dụng một cấu trúc lưu trữ riêng biệt cho mỗi cột. Mỗi cột được coi như một mảng dữ liệu độc lập, cho phép nén dữ liệu hiệu quả hơn vì các giá trị trong cùng một cột thường có cùng kiểu dữ liệu và xu hướng lặp lại. Các hệ thống Column Database hiện đại như Apache Parquet, Apache ORC, hay Google BigQuery đều áp dụng kỹ thuật nén mạnh mẽ như run-length encoding, dictionary encoding, hay bit-packing để giảm dung lượng lưu trữ.
Cơ chế nén dữ liệu trong Column Database
Khả năng nén dữ liệu là một trong những lợi thế lớn nhất của Column Database. Khi dữ liệu cùng loại được lưu liên tiếp, các thuật toán nén hoạt động hiệu quả hơn nhiều so với lưu trữ hàng. Ví dụ, cột “Thành phố” trong bảng khách hàng có thể chỉ chứa vài giá trị lặp đi lặp lại như “Hà Nội”, “TP.HCM”, “Đà Nẵng”. Column Database có thể nén cột này xuống chỉ còn vài byte thay vì lưu trữ toàn bộ chuỗi ký tự cho mỗi bản ghi. Các nghiên cứu cho thấy mức nén có thể đạt từ 5x đến 10x so với lưu trữ hàng thông thường.
Xử lý truy vấn trong Column Database
Khi một truy vấn được thực thi, Column Database chỉ đọc các cột cần thiết thay vì phải quét toàn bộ hàng. Điều này giảm đáng kể lượng I/O từ đĩa cứng. Ví dụ, truy vấn tính tổng doanh thu theo tháng từ bảng giao dịch có 100 cột sẽ chỉ cần đọc 2 cột: “Doanh thu” và “Tháng”. Trong cơ sở dữ liệu hàng, hệ thống buộc phải đọc toàn bộ 100 cột của mỗi hàng, gây lãng phí tài nguyên nghiêm trọng.
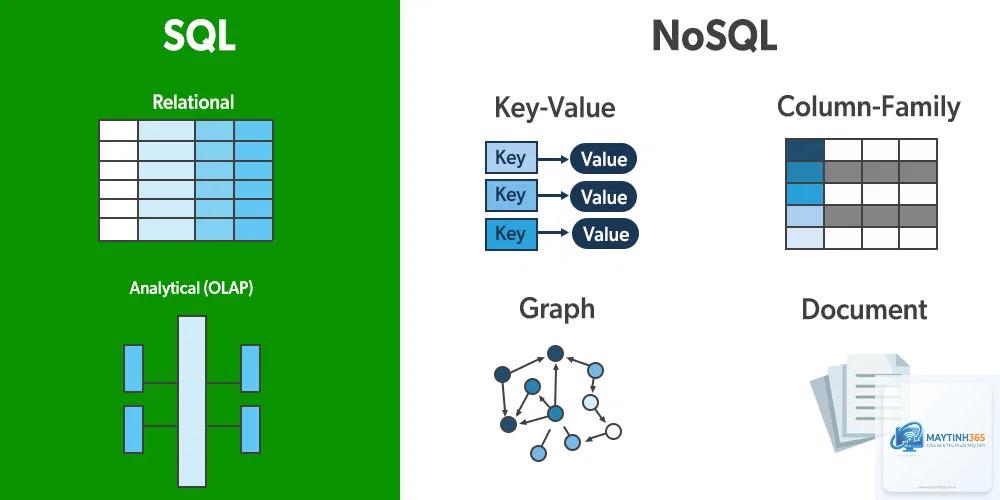
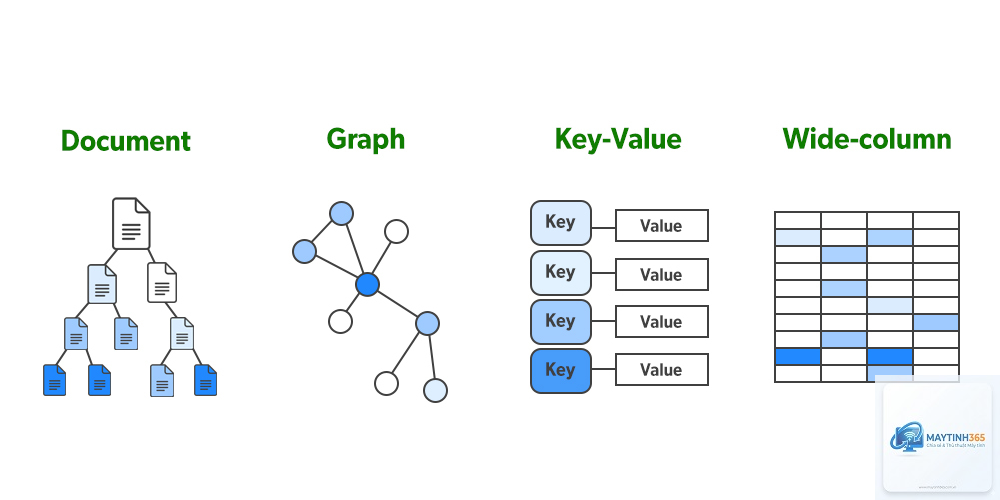
Phân loại các hệ thống Column Database phổ biến
Loại
Ví dụ
Đặc điểm chính
Column-Oriented DBMS thuần túy
Apache Cassandra, MonetDB
Lưu trữ hoàn toàn theo cột, tối ưu cho ghi và đọc phân tích
Hybrid Row-Column
Google BigQuery, Amazon Redshift
Kết hợp lưu trữ hàng và cột, linh hoạt cho nhiều loại truy vấn
Columnar Storage Formats
Apache Parquet, Apache ORC
Định dạng tệp lưu trữ cột, thường dùng trong Hadoop và Spark
In-Memory Column Database
SAP HANA, MemSQL
Lưu trữ dữ liệu trong RAM, tốc độ truy vấn cực nhanh
So sánh Column Database và Row Database
Tiêu chí
Column Database
Row Database
Cách lưu trữ
Lưu theo từng cột riêng biệt
Lưu theo từng hàng hoàn chỉnh
Hiệu suất đọc
Tối ưu cho đọc nhiều cột ít, hàng nhiều
Tối ưu cho đọc toàn bộ hàng
Hiệu suất ghi
Chậm hơn do phải ghi nhiều vị trí
Nhanh hơn, ghi một lần cho mỗi hàng
Khả năng nén
Cao, có thể đạt 5-10 lần
Thấp, do dữ liệu không đồng nhất
Ứng dụng chính
Phân tích, báo cáo, OLAP
Giao dịch, OLTP, ứng dụng web
Ví dụ
ClickHouse, BigQuery, Redshift
MySQL, PostgreSQL, Oracle
Lợi ích vượt trội của Column Database
Tốc độ truy vấn phân tích nhanh hơn 10-100 lần
Column Database có thể tăng tốc độ truy vấn phân tích lên đến 100 lần so với cơ sở dữ liệu hàng truyền thống. Lý do là vì chỉ cần đọc các cột liên quan, giảm lượng dữ liệu cần xử lý xuống mức tối thiểu. Các hệ thống như ClickHouse có thể xử lý hàng tỷ hàng dữ liệu chỉ trong vài giây cho các truy vấn tổng hợp.
Nhờ khả năng nén mạnh mẽ, Column Database giảm dung lượng lưu trữ từ 3 đến 10 lần so với lưu trữ hàng. Điều này không chỉ tiết kiệm chi phí phần cứng mà còn cải thiện hiệu suất đọc vì dữ liệu nén được truyền tải nhanh hơn qua mạng và bộ nhớ đệm.
Khả năng mở rộng theo chiều ngang
Hầu hết các Column Database hiện đại được thiết kế để chạy trên các cụm máy chủ phân tán. Kiến trúc này cho phép mở rộng dung lượng lưu trữ và khả năng xử lý bằng cách thêm nhiều nút vào cụm. Google BigQuery và Amazon Redshift có thể xử lý petabyte dữ liệu mà không cần thay đổi kiến trúc ứng dụng.
Hạn chế và thách thức khi sử dụng Column Database
Hiệu suất ghi kém hơn
Column Database không phù hợp cho các ứng dụng yêu cầu ghi dữ liệu liên tục với tần suất cao. Mỗi lần ghi một hàng mới, hệ thống phải cập nhật nhiều tệp cột khác nhau, gây ra độ trễ đáng kể. Đây là lý do Column Database hiếm khi được dùng cho các hệ thống giao dịch trực tuyến.
Không tối ưu cho truy vấn lấy toàn bộ hàng
Khi ứng dụng cần lấy toàn bộ thông tin của một bản ghi, Column Database hoạt động kém hiệu quả hơn. Việc phải đọc từ nhiều tệp cột khác nhau và kết hợp chúng lại tạo ra overhead đáng kể. Các ứng dụng web hiển thị chi tiết sản phẩm hoặc thông tin người dùng thường phù hợp với Row Database hơn.
Độ phức tạp trong quản trị
Quản trị Column Database đòi hỏi kiến thức chuyên sâu hơn so với cơ sở dữ liệu quan hệ truyền thống. Việc tối ưu hóa lược đồ, lựa chọn khóa phân vùng, và cấu hình nén dữ liệu là những kỹ năng cần thiết để khai thác tối đa hiệu suất.
Ứng dụng thực tế của Column Database
Phân tích dữ liệu lớn và Business Intelligence
Column Database là xương sống của hầu hết các hệ thống Business Intelligence hiện đại. Các công ty như Uber, Netflix, và Airbnb sử dụng Column Database để phân tích hành vi người dùng, tối ưu hóa trải nghiệm và đưa ra quyết định kinh doanh dựa trên dữ liệu thời gian thực.
Hệ thống báo cáo tài chính và kế toán
Trong lĩnh vực tài chính, Column Database được dùng để xử lý các báo cáo tổng hợp từ hàng triệu giao dịch. Các ngân hàng sử dụng ClickHouse hoặc Vertica để tính toán số dư cuối ngày, phát hiện gian lận, và tạo báo cáo tuân thủ quy định trong thời gian ngắn.
IoT và dữ liệu cảm biến
Các hệ thống Internet of Things tạo ra lượng dữ liệu khổng lồ từ hàng triệu cảm biến. Column Database như InfluxDB và TimescaleDB được tối ưu hóa để lưu trữ và truy vấn dữ liệu chuỗi thời gian, cho phép phân tích xu hướng và phát hiện bất thường trong thời gian thực.
Hệ thống khuyến nghị và cá nhân hóa
Các nền tảng thương mại điện tử sử dụng Column Database để lưu trữ lịch sử mua hàng và hành vi duyệt web của hàng triệu người dùng. Dữ liệu này được truy vấn nhanh chóng để đưa ra các đề xuất sản phẩm cá nhân hóa, tăng tỷ lệ chuyển đổi.
Nhiều đội ngũ kỹ thuật mắc sai lầm khi cố gắng dùng Column Database cho các ứng dụng giao dịch trực tuyến như giỏ hàng, đặt vé, hay xử lý đơn hàng. Kết quả là hiệu suất ghi kém và độ trễ cao, gây ảnh hưởng trực tiếp đến trải nghiệm người dùng.
Thiết kế lược đồ không phù hợp
Việc thiết kế quá nhiều cột hoặc sử dụng các kiểu dữ liệu không tối ưu làm giảm hiệu quả nén và tốc độ truy vấn. Các chuyên gia khuyên nên giới hạn số lượng cột trong một bảng và sử dụng các kiểu dữ liệu nhỏ gọn như INT thay vì STRING khi có thể.
Bỏ qua việc phân vùng dữ liệu
Không phân vùng dữ liệu đúng cách là nguyên nhân hàng đầu gây ra hiệu suất kém trong Column Database. Phân vùng theo thời gian hoặc theo khóa tự nhiên giúp hệ thống chỉ quét một phần nhỏ dữ liệu, cải thiện tốc độ truy vấn lên nhiều lần.
Lưu ý quan trọng khi chọn Column Database
Trước khi quyết định sử dụng Column Database, cần đánh giá kỹ lưỡng khối lượng dữ liệu, tần suất truy vấn và yêu cầu về thời gian thực. Column Database phát huy tối đa sức mạnh khi xử lý từ hàng trăm triệu bản ghi trở lên với các truy vấn tổng hợp phức tạp. Đối với các hệ thống nhỏ dưới 10 triệu bản ghi, sự khác biệt về hiệu suất có thể không đáng kể.
Chi phí vận hành cũng là yếu tố cần cân nhắc. Các dịch vụ Column Database đám mây như Google BigQuery tính phí dựa trên lượng dữ liệu quét, có thể trở nên đắt đỏ nếu truy vấn không được tối ưu hóa. Việc sử dụng các định dạng lưu trữ cột như Parquet kết hợp với Apache Spark có thể là giải pháp tiết kiệm chi phí hơn cho các doanh nghiệp vừa và nhỏ.
Câu hỏi thường gặp về Column Database
Column Database có thay thế hoàn toàn được cơ sở dữ liệu quan hệ không?
Không. Column Database và Row Database phục vụ các mục đích khác nhau. Column Database tối ưu cho phân tích và báo cáo, trong khi Row Database phù hợp cho xử lý giao dịch. Hầu hết các kiến trúc hiện đại đều kết hợp cả hai loại để tận dụng ưu điểm của từng loại.
Học Column Database có khó không?
Nếu đã có kiến thức về SQL và cơ sở dữ liệu quan hệ, việc học Column Database tương đối dễ dàng. Các khái niệm cơ bản như SELECT, WHERE, GROUP BY vẫn được giữ nguyên. Điểm khác biệt chính nằm ở cách thiết kế lược đồ và tối ưu hóa truy vấn cho dữ liệu lớn.
Column Database có hỗ trợ ACID không?
Hầu hết các Column Database ưu tiên hiệu suất hơn tính toàn vẹn giao dịch. Một số hệ thống như Google BigQuery hỗ trợ ACID ở mức độ nhất định, nhưng không mạnh mẽ như các cơ sở dữ liệu quan hệ truyền thống. Điều này khiến chúng không phù hợp cho các ứng dụng yêu cầu tính nhất quán giao dịch cao.
Nên chọn Column Database nào cho dự án mới?
Lựa chọn phụ thuộc vào quy mô và ngân sách. ClickHouse là lựa chọn mã nguồn mở mạnh mẽ cho các doanh nghiệp tự triển khai. Google BigQuery phù hợp cho các dự án đám mây với khả năng mở rộng không giới hạn. Apache Cassandra thích hợp cho các hệ thống yêu cầu khả năng chịu lỗi cao và ghi dữ liệu liên tục.
Kết luận
Column Database đã thay đổi cách chúng ta tiếp cận và xử lý dữ liệu lớn. Với khả năng nén vượt trội, tốc độ truy vấn phân tích nhanh chóng và kiến trúc phân tán linh hoạt, Column Database là công cụ không thể thiếu trong kho vũ khí của các kỹ sư dữ liệu và nhà phân tích hiện đại. Tuy nhiên, việc hiểu rõ ưu nhược điểm và ứng dụng phù hợp là chìa khóa để khai thác tối đa sức mạnh của công nghệ này. Khi được triển khai đúng cách, Column Database không chỉ giúp tiết kiệm chi phí mà còn mở ra những khả năng phân tích mới mà trước đây không thể thực hiện được với cơ sở dữ liệu truyền thống.