Trong thế giới kỹ thuật số, việc hiển thị chính xác văn bản từ nhiều ngôn ngữ khác nhau là một thách thức lớn. UTF-8 là gì? Đây là bảng mã ký tự toàn cầu, được thiết kế để giải quyết vấn đề tương thích giữa các hệ thống máy tính. UTF-8 (Unicode Transformation Format – 8-bit) là chuẩn mã hóa ký tự linh hoạt, cho phép biểu diễn hầu hết mọi ký tự từ các ngôn ngữ trên thế giới, từ tiếng Anh, tiếng Việt, tiếng Trung đến tiếng Ả Rập. Với hơn 95% website hiện nay sử dụng UTF-8, đây là tiêu chuẩn không thể thiếu trong lập trình web, quản lý cơ sở dữ liệu và truyền thông dữ liệu.
UTF-8 là một phương pháp mã hóa Unicode, sử dụng từ 1 đến 4 byte để biểu diễn mỗi ký tự. Khác với các bảng mã cũ như ASCII chỉ hỗ trợ 128 ký tự, UTF-8 có thể mã hóa hơn 1,1 triệu ký tự. Điểm đặc biệt là UTF-8 tương thích ngược với ASCII: 128 ký tự đầu tiên của UTF-8 giống hệt ASCII, chỉ dùng 1 byte. Các ký tự phức tạp hơn như chữ có dấu tiếng Việt, chữ Hán hay emoji sử dụng 2-4 byte.
Cấu trúc byte trong UTF-8
Mỗi ký tự trong UTF-8 được mã hóa theo một mẫu bit cụ thể. Byte đầu tiên xác định độ dài của ký tự, các byte tiếp theo bắt đầu bằng “10” để đánh dấu chúng là byte tiếp nối. Cụ thể:
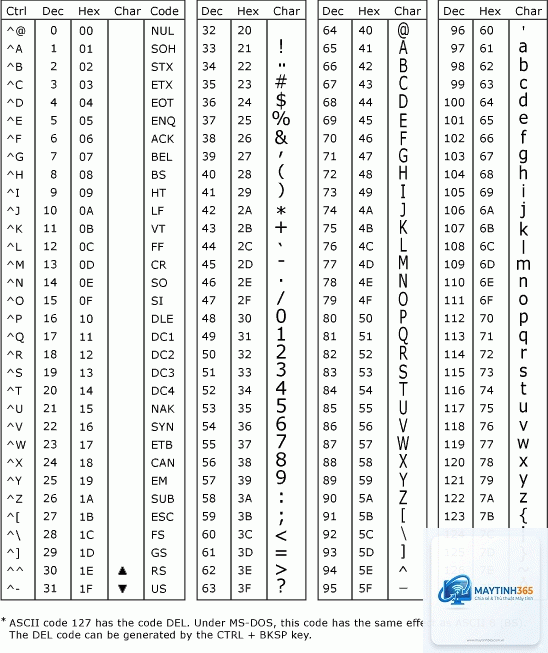
Ký tự 1 byte: 0xxxxxxx (tương thích ASCII, mã từ U+0000 đến U+007F)
Ký tự 2 byte: 110xxxxx 10xxxxxx (mã từ U+0080 đến U+07FF)
Ký tự 3 byte: 1110xxxx 10xxxxxx 10xxxxxx (mã từ U+0800 đến U+FFFF)
Ký tự 4 byte: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (mã từ U+10000 đến U+10FFFF)
Ví dụ: Ký tự “ê” trong tiếng Việt có mã Unicode U+00EA, được mã hóa thành 2 byte: 11000011 10101010 trong UTF-8. Trong khi đó, ký tự “A” (U+0041) chỉ cần 1 byte: 01000001.
Lịch sử phát triển của UTF-8 và Unicode
Trước khi UTF-8 ra đời, mỗi quốc gia hoặc khu vực sử dụng các bảng mã riêng biệt. Tiếng Việt có VNI, TCVN3, VISCII. Tiếng Nhật có Shift JIS, EUC-JP. Điều này gây ra vấn đề nghiêm trọng khi trao đổi dữ liệu quốc tế. Năm 1991, Unicode Consortium được thành lập để tạo ra một bảng mã thống nhất. Ken Thompson và Rob Pike tại Bell Labs đã phát triển UTF-8 vào năm 1992, và nhanh chóng trở thành tiêu chuẩn trên Internet.
Sự khác biệt giữa Unicode và UTF-8
Nhiều người nhầm lẫn giữa Unicode và UTF-8. Unicode là bảng mã ký tự, gán mỗi ký tự một số duy nhất (code point). UTF-8 là phương pháp mã hóa các số đó thành dạng nhị phân để lưu trữ và truyền tải. Unicode định nghĩa “cái gì”, UTF-8 định nghĩa “như thế nào”. Các phương pháp mã hóa Unicode khác bao gồm UTF-16 (dùng 2 hoặc 4 byte) và UTF-32 (dùng 4 byte cố định).
Ưu điểm vượt trội của UTF-8 so với các bảng mã khác
UTF-8 chiếm ưu thế tuyệt đối nhờ nhiều lợi thế kỹ thuật. Bảng dưới đây so sánh UTF-8 với các bảng mã phổ biến khác:
Tiêu chí
UTF-8
ASCII
UTF-16
ISO-8859-1
Số byte mỗi ký tự
1-4 byte
1 byte
2 hoặc 4 byte
1 byte
Số ký tự hỗ trợ
Hơn 1,1 triệu
128
Hơn 1,1 triệu
256
Tương thích ASCII
Có
Có
Không
Một phần
Kích thước file văn bản tiếng Anh
Nhỏ nhất
Nhỏ nhất
Lớn gấp đôi
Nhỏ nhất
Kích thước file văn bản tiếng Việt
Trung bình
Không hỗ trợ
Lớn hơn
Không hỗ trợ
Hỗ trợ emoji
Có
Không
Có
Không
Tiết kiệm băng thông và dung lượng lưu trữ
Đối với văn bản chủ yếu bằng tiếng Anh, UTF-8 chỉ dùng 1 byte mỗi ký tự, tương đương ASCII. Trong khi đó, UTF-16 luôn dùng ít nhất 2 byte, làm tăng gấp đôi dung lượng. Với các trang web lớn, sự khác biệt này có thể lên đến hàng gigabyte. UTF-8 cũng tối ưu cho giao thức HTTP vì không chứa byte null (0x00) trong các ký tự thông thường, tránh lỗi khi truyền dữ liệu.
Ứng dụng thực tế của UTF-8 trong phát triển web
Hầu hết các công nghệ web hiện đại đều mặc định sử dụng UTF-8. Khi xây dựng website, việc khai báo đúng bảng mã là bước cơ bản nhưng quan trọng. Trong HTML, thẻ meta sau đây được đặt trong phần head:
<meta charset=”UTF-8″>
Đối với cơ sở dữ liệu MySQL, cần thiết lập bảng và cột sử dụng utf8mb4 thay vì utf8, vì utf8 trong MySQL chỉ hỗ trợ tối đa 3 byte, không đủ cho emoji và một số ký tự đặc biệt. Lệnh tạo bảng mẫu:
CREATE TABLE bai_viet (noi_dung TEXT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci);
UTF-8 trong lập trình backend
Các ngôn ngữ lập trình như Python, PHP, Java, JavaScript đều hỗ trợ UTF-8. Trong Python 3, chuỗi mặc định là Unicode, và việc mã hóa/giải mã được thực hiện qua phương thức.encode(‘utf-8’) và.decode(‘utf-8’). Trong PHP, các hàm như mb_convert_encoding() giúp xử lý UTF-8 chính xác. Lập trình viên cần đảm bảo toàn bộ pipeline từ input, xử lý đến output đều sử dụng UTF-8 để tránh lỗi hiển thị.
Sai lầm thường gặp khi sử dụng UTF-8 và cách khắc phục
Dù UTF-8 phổ biến, nhiều lập trình viên vẫn mắc phải những lỗi cơ bản. Giải pháp: Luôn đặt <meta charset=”UTF-8″> ngay sau thẻ <head> và thiết lập header Content-Type: text/html; charset=UTF-8 trên server.
Lưu file nguồn không đúng encoding: File HTML, CSS, JavaScript được lưu với encoding khác UTF-8 (ví dụ ANSI). Giải pháp: Cấu hình editor (VS Code, Sublime Text) mặc định lưu file với encoding UTF-8.
Nhầm lẫn giữa utf8 và utf8mb4 trong MySQL: Kiểu utf8 chỉ hỗ trợ 3 byte, không lưu được emoji. Giải pháp: Sử dụng utf8mb4 cho mọi bảng và cột chứa văn bản.
Không xử lý chuỗi đầu vào từ form: Dữ liệu gửi từ form HTML có thể bị mã hóa sai nếu trang không dùng UTF-8. Giải pháp: Đảm bảo form có thuộc tính accept-charset=”UTF-8″.
Lỗi double encoding: Dữ liệu đã được mã hóa UTF-8 lại bị mã hóa thêm lần nữa, tạo ra ký tự lạ. Giải pháp: Kiểm tra luồng dữ liệu, chỉ mã hóa một lần duy nhất.
Lưu ý quan trọng khi chuyển đổi sang UTF-8
Khi nâng cấp hệ thống từ bảng mã cũ lên UTF-8, cần thực hiện cẩn thận để tránh mất dữ liệu. Sao lưu toàn bộ cơ sở dữ liệu trước khi thực hiện. Quy trình chuyển đổi cơ sở dữ liệu MySQL gồm các bước: xuất dữ liệu với bảng mã cũ, chuyển file SQL sang UTF-8 bằng công cụ như iconv, sau đó import vào cơ sở dữ liệu mới với charset utf8mb4. Kiểm tra kỹ các ký tự đặc biệt như dấu ngoặc kép, dấu nháy đơn có thể bị hỏng trong quá trình chuyển đổi.
UTF-8 và SEO: Tác động đến thứ hạng tìm kiếm
Công cụ tìm kiếm như Google ưu tiên các trang web sử dụng UTF-8 vì khả năng hiển thị nội dung đa ngôn ngữ chính xác. Trang web không dùng UTF-8 có thể gặp lỗi hiển thị tiêu đề, mô tả meta, dẫn đến tỷ lệ nhấp chuột thấp. Googlebot đọc nội dung dựa trên bảng mã được khai báo, nếu khai báo sai, nội dung có thể bị hiểu nhầm, ảnh hưởng đến index. Sử dụng UTF-8 cũng giúp URL chứa ký tự Unicode được xử lý đúng, cải thiện trải nghiệm người dùng.
Câu hỏi thường gặp về UTF-8
UTF-8 có hỗ trợ tiếng Việt không?
Có, UTF-8 hỗ trợ đầy đủ tiếng Việt với tất cả các dấu thanh và chữ cái có dấu như ă, â, ê, ô, ơ, ư. Mỗi ký tự tiếng Việt thường được mã hóa bằng 2 hoặc 3 byte trong UTF-8.
Sự khác nhau giữa UTF-8 và Unicode là gì?
Unicode là bảng tiêu chuẩn gán mã số cho mỗi ký tự, còn UTF-8 là phương pháp mã hóa các mã số đó thành dạng nhị phân. Unicode định nghĩa ký tự, UTF-8 định nghĩa cách lưu trữ.
Tại sao UTF-8 lại phổ biến hơn UTF-16?
UTF-8 tiết kiệm dung lượng cho văn bản tiếng Anh và các ngôn ngữ dùng ký tự Latin, tương thích ngược với ASCII, không chứa byte null, và dễ dàng xử lý trong các hệ thống cũ. UTF-16 thường được dùng trong môi trường Windows và Java.
Làm thế nào để kiểm tra một file có đúng UTF-8 không?
Sử dụng lệnh file -i ten_file trên Linux/macOS hoặc dùng Notepad++ trên Windows (Encoding menu hiển thị encoding hiện tại). Công cụ trực tuyến như W3C Validator cũng kiểm tra được charset của trang web.
UTF-8 có hỗ trợ emoji không?
Có, emoji nằm trong khoảng mã U+1F600 đến U+1F64F và các khoảng khác, được mã hóa bằng 4 byte trong UTF-8. Để lưu emoji trong MySQL, cần sử dụng utf8mb4 thay vì utf8.
Có nên chuyển website từ bảng mã cũ sang UTF-8 không?
Rất nên. UTF-8 là tiêu chuẩn toàn cầu, giúp website hiển thị chính xác trên mọi thiết bị và trình duyệt, cải thiện SEO, và tương thích với các công nghệ hiện đại. Quá trình chuyển đổi cần được thực hiện cẩn thận để tránh mất dữ liệu.
Kết luận
UTF-8 là nền tảng không thể thiếu của Internet hiện đại, cho phép hàng tỷ người dùng trên thế giới giao tiếp bằng ngôn ngữ mẹ đẻ của họ. Từ khái niệm UTF-8 là gì, cách nó mã hóa ký tự, đến ứng dụng trong lập trình và SEO, việc hiểu rõ bảng mã này giúp lập trình viên và chủ website tránh được nhiều lỗi kỹ thuật. Với ưu điểm vượt trội về tính tương thích, hiệu quả lưu trữ và hỗ trợ đa ngôn ngữ, UTF-8 chắc chắn sẽ tiếp tục là tiêu chuẩn mã hóa ký tự thống trị trong nhiều thập kỷ tới. Hãy đảm bảo mọi dự án web của bạn đều sử dụng UTF-8 ngay từ đầu để tận dụng tối đa lợi ích mà nó mang lại.