Trong thế giới số hiện đại, mỗi ký tự bạn nhìn thấy trên màn hình – từ chữ cái Latinh, chữ Hán, cho đến biểu tượng cảm xúc – đều được máy tính xử lý dưới dạng các con số nhị phân. Unicode UTF-8 là gì? Đây là một chuẩn mã hóa ký tự cho phép máy tính hiển thị và trao đổi văn bản từ hầu hết mọi ngôn ngữ trên thế giới một cách thống nhất. UTF-8 là phương pháp mã hóa phổ biến nhất của bảng mã Unicode, chiếm hơn 95% lưu lượng truy cập web toàn cầu. Bài viết này sẽ giải thích chi tiết về bản chất, cách hoạt động, lợi ích và ứng dụng thực tế của Unicode UTF-8.
Unicode là một tiêu chuẩn công nghiệp quốc tế được thiết kế để mã hóa, biểu diễn và xử lý văn bản từ hầu hết các hệ thống chữ viết trên thế giới. Thay vì chỉ hỗ trợ một vài ngôn ngữ như ASCII, Unicode cung cấp một mã số duy nhất cho mỗi ký tự, bất kể nền tảng, thiết bị hay ngôn ngữ nào. Phiên bản Unicode 15.0 hiện tại hỗ trợ hơn 149.000 ký tự từ 161 hệ thống chữ viết khác nhau.
UTF-8 là gì?
UTF-8 (Unicode Transformation Format – 8-bit) là một phương pháp mã hóa ký tự có độ dài thay đổi cho Unicode. Nó sử dụng từ 1 đến 4 byte để biểu diễn mỗi ký tự. UTF-8 được thiết kế tương thích ngược với ASCII, nghĩa là mọi tài liệu ASCII hợp lệ đều là tài liệu UTF-8 hợp lệ. Điều này giải thích tại sao UTF-8 trở thành lựa chọn hàng đầu cho web, email và nhiều ứng dụng phần mềm.
UTF-8 hoạt động dựa trên cơ chế mã hóa có độ dài thay đổi. Mỗi ký tự Unicode được gán một mã số (code point), và UTF-8 sẽ chuyển đổi mã số này thành một chuỗi byte cụ thể. Cấu trúc mã hóa như sau:
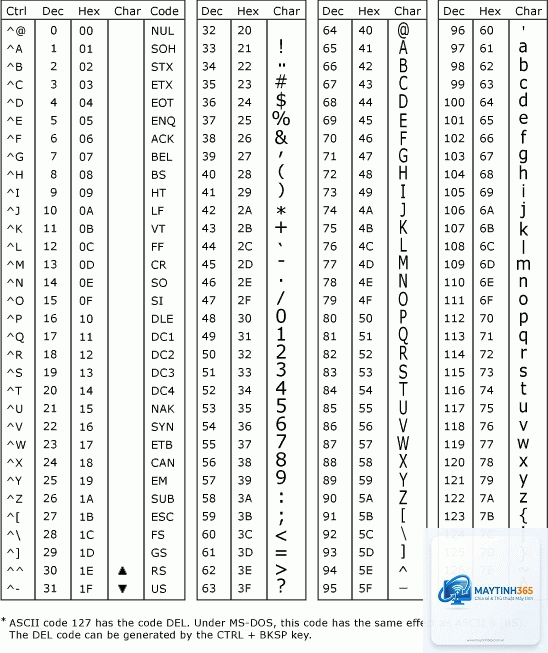
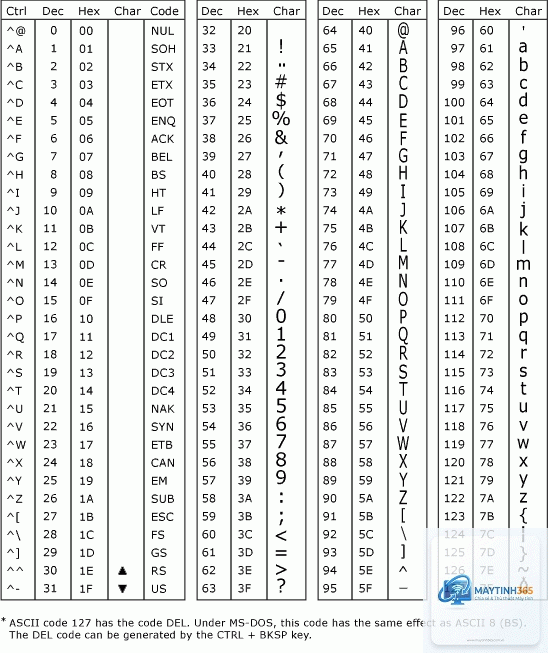
Ký tự ASCII (U+0000 đến U+007F): 1 byte, bit đầu tiên là 0
Ký tự Latin mở rộng (U+0080 đến U+07FF): 2 byte, bắt đầu bằng 110xxxxx
Ký tự đa ngữ cơ bản (U+0800 đến U+FFFF): 3 byte, bắt đầu bằng 1110xxxx
Ký tự bổ sung (U+10000 đến U+10FFFF): 4 byte, bắt đầu bằng 11110xxx
Ví dụ cụ thể: Ký tự ‘A’ (U+0041) trong UTF-8 chỉ chiếm 1 byte là 0x41. Trong khi đó, ký tự ‘あ’ (U+3042) trong tiếng Nhật chiếm 3 byte: 0xE3 0x81 0x82.
Unicode UTF-8 cho phép hiển thị đồng thời nhiều ngôn ngữ trong cùng một văn bản. Một trang web có thể chứa tiếng Việt, tiếng Trung, tiếng Ả Rập và tiếng Nga mà không gặp lỗi hiển thị. Điều này đặc biệt quan trọng trong thời đại toàn cầu hóa và thương mại điện tử xuyên biên giới.
Tiết kiệm băng thông và dung lượng
Đối với văn bản chủ yếu sử dụng ký tự Latin (như tiếng Anh, tiếng Việt không dấu), UTF-8 chỉ tốn 1 byte mỗi ký tự. So với UTF-16 hay UTF-32, UTF-8 giảm đáng kể dung lượng lưu trữ và băng thông truyền tải. Một trang web tiếng Anh trung bình có thể nhỏ hơn 50% so với khi dùng UTF-16.
Không có vấn đề endianness
UTF-8 không bị ảnh hưởng bởi thứ tự byte (big-endian hay little-endian) của bộ xử lý. Điều này giúp dữ liệu UTF-8 luôn nhất quán khi di chuyển giữa các hệ thống khác nhau, từ máy tính Windows đến máy chủ Linux hay thiết bị di động.
Hạn chế và thách thức khi sử dụng Unicode UTF-8
Kích thước không đồng nhất
Do sử dụng độ dài thay đổi, việc tính toán vị trí ký tự trong chuỗi UTF-8 phức tạp hơn so với các chuẩn có độ dài cố định. Các thao tác như cắt chuỗi, tìm kiếm hay đếm ký tự đòi hỏi phải phân tích cú pháp đúng cách, nếu không có thể dẫn đến lỗi hiển thị hoặc mất dữ liệu.
Một số ký tự Unicode có thể được biểu diễn bằng nhiều cách khác nhau (normalization forms). Ví dụ, chữ ‘é’ có thể là một ký tự đơn (U+00E9) hoặc tổ hợp của ‘e’ (U+0065) và dấu sắc (U+0301). Điều này gây khó khăn cho việc so sánh chuỗi và tìm kiếm văn bản nếu không chuẩn hóa trước.
Ứng dụng thực tế của Unicode UTF-8
Phát triển web và ứng dụng
Hầu hết các trang web hiện đại đều sử dụng UTF-8 làm bảng mã mặc định. HTML5 khuyến nghị sử dụng UTF-8 trong thẻ meta charset. Các framework phổ biến như React, Angular, Vue.js đều hỗ trợ UTF-8 một cách tự nhiên. API RESTful và JSON cũng mặc định sử dụng UTF-8 để trao đổi dữ liệu.
Cơ sở dữ liệu và lưu trữ
MySQL, PostgreSQL, MongoDB và nhiều hệ quản trị cơ sở dữ liệu khác hỗ trợ UTF-8. Khi thiết kế database cho ứng dụng đa ngôn ngữ, việc chọn collation utf8mb4 trong MySQL là bắt buộc để hỗ trợ đầy đủ các ký tự Unicode, bao gồm cả biểu tượng cảm xúc (emoji).
Hệ điều hành và tập tin
Linux, macOS và Windows đều hỗ trợ UTF-8 trong tên tập tin và đường dẫn. Hệ thống tập tin NTFS của Windows sử dụng UTF-16 nội bộ nhưng chuyển đổi qua UTF-8 khi giao tiếp với ứng dụng. Các định dạng tập tin phổ biến như XML, JSON, CSV cũng khuyến nghị sử dụng UTF-8.
Sai lầm thường gặp khi làm việc với Unicode UTF-8
Không khai báo charset trong HTML
Nhiều lập trình viên quên thêm thẻ meta charset=”UTF-8″ trong trang web. Điều này khiến trình duyệt tự động phát hiện bảng mã, dễ dẫn đến lỗi hiển thị ký tự tiếng Việt, tiếng Trung hoặc các ngôn ngữ đặc biệt.
Sử dụng sai collation trong MySQL
Khi sử dụng MySQL, nhiều người chọn utf8_general_ci thay vì utf8mb4_unicode_ci. Bảng mã utf8 trong MySQL thực chất chỉ hỗ trợ tối đa 3 byte, không thể lưu trữ emoji và một số ký tự Unicode mở rộng. Điều này gây mất dữ liệu khi người dùng nhập biểu tượng cảm xúc.
Xử lý chuỗi không đúng cách
Các hàm xử lý chuỗi truyền thống như strlen() trong PHP hay length() trong JavaScript đếm số byte thay vì số ký tự khi làm việc với UTF-8. Điều này dẫn đến cắt chuỗi sai vị trí, làm hỏng ký tự Unicode và gây lỗi hiển thị.
Trước khi lưu trữ hoặc so sánh dữ liệu văn bản, cần chuẩn hóa Unicode về một dạng thống nhất. Có bốn dạng chuẩn hóa: NFC, NFD, NFKC và NFKD. NFC là dạng được khuyến nghị cho hầu hết ứng dụng web vì nó kết hợp các ký tự tổ hợp thành dạng đơn giản nhất.
Kiểm tra bảng mã đầu vào
Khi nhận dữ liệu từ người dùng hoặc từ hệ thống bên ngoài, luôn kiểm tra và chuyển đổi về UTF-8 nếu cần. Sử dụng các thư viện như mb_detect_encoding() trong PHP hay iconv trong Python để phát hiện và chuyển đổi bảng mã tự động.
Sao lưu và phục hồi dữ liệu
Khi sao lưu cơ sở dữ liệu có chứa dữ liệu UTF-8, đảm bảo công cụ sao lưu hỗ trợ đúng bảng mã. Sử dụng mysqldump với tùy chọn –default-character-set=utf8mb4 để tránh mất dữ liệu khi phục hồi.
Câu hỏi thường gặp về Unicode UTF-8
Sự khác biệt giữa Unicode và UTF-8 là gì?
Unicode là tiêu chuẩn gán mã số duy nhất cho mỗi ký tự, trong khi UTF-8 là phương pháp mã hóa các mã số đó thành dạng byte để lưu trữ và truyền tải. Unicode định nghĩa ký tự là gì, UTF-8 quyết định cách biểu diễn ký tự đó trong máy tính.
Tại sao UTF-8 được sử dụng phổ biến trên web?
UTF-8 chiếm ưu thế nhờ tương thích ngược với ASCII, tiết kiệm dung lượng cho văn bản Latin, không phụ thuộc vào thứ tự byte và hỗ trợ đầy đủ mọi ngôn ngữ. Hầu hết trình duyệt, máy chủ web và công cụ phát triển đều mặc định sử dụng UTF-8.
Làm thế nào để chuyển đổi văn bản sang UTF-8?
Có thể sử dụng các công cụ trực tuyến, trình soạn thảo văn bản như Notepad++ với chức năng Encoding, hoặc các lệnh dòng lệnh như iconv trong Linux. Trong lập trình, hầu hết ngôn ngữ đều có hàm chuyển đổi bảng mã tích hợp sẵn.
UTF-8 có hỗ trợ tiếng Việt không?
Có, UTF-8 hỗ trợ đầy đủ tiếng Việt với tất cả dấu thanh và ký tự đặc biệt. Tiếng Việt sử dụng bảng chữ cái Latin mở rộng, mỗi ký tự có dấu thường chiếm 2-3 byte trong UTF-8. Đây là lựa chọn tối ưu cho các trang web và ứng dụng tiếng Việt.
Emoji có phải là một phần của Unicode UTF-8 không?
Emoji là một phần của tiêu chuẩn Unicode và được mã hóa bằng UTF-8. Mỗi emoji thường chiếm 4 byte trong UTF-8. Để hiển thị emoji đúng cách, cần sử dụng cơ sở dữ liệu hỗ trợ utf8mb4 (MySQL) và font chữ có hỗ trợ emoji.
Kết luận
Unicode UTF-8 là chuẩn mã hóa ký tự không thể thiếu trong thời đại số hóa toàn cầu. Với khả năng hỗ trợ hầu hết ngôn ngữ trên thế giới, tương thích ngược với ASCII và tiết kiệm dung lượng, UTF-8 đã trở thành lựa chọn mặc định cho web, cơ sở dữ liệu và ứng dụng đa nền tảng. Hiểu rõ về Unicode UTF-8 là gì và cách triển khai đúng cách giúp tránh các lỗi hiển thị, mất dữ liệu và đảm bảo trải nghiệm người dùng tốt nhất. Khi phát triển bất kỳ ứng dụng nào có xử lý văn bản, việc áp dụng UTF-8 ngay từ đầu là quyết định chiến lược giúp tiết kiệm thời gian và công sức về sau.