Trong kỷ nguyên số, dữ liệu được ví như “dầu mỏ” của nền kinh tế. Tuy nhiên, các quy định về quyền riêng tư như GDPR (Châu Âu) hay Nghị định bảo vệ dữ liệu cá nhân (Việt Nam) đang đặt ra thách thức lớn cho việc thu thập và tập trung dữ liệu để huấn luyện trí tuệ nhân tạo (AI). Federated Learning là gì mà có thể giải quyết bài toán nan giải này? Đây là một phương pháp học máy đột phá, cho phép huấn luyện mô hình AI trên nhiều thiết bị hoặc máy chủ cục bộ mà không cần di chuyển dữ liệu thô về một trung tâm duy nhất. Nói cách khác, dữ liệu không đi đến mô hình, mà mô hình sẽ đến với dữ liệu.
Bản chất của Federated Learning: Cách mạng hóa quy trình huấn luyện AI
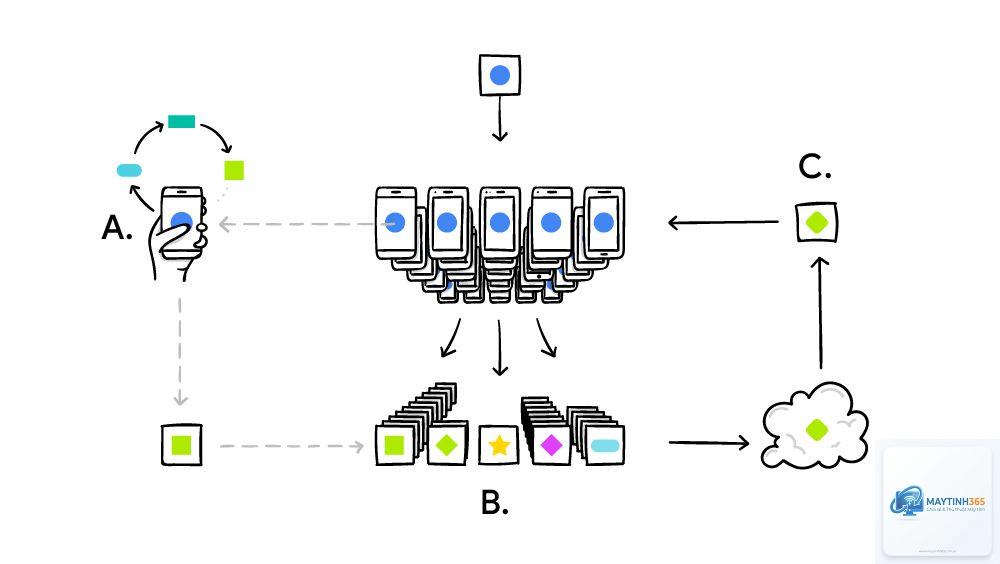
Để hiểu rõ Federated Learning là gì, hãy hình dung một kịch bản đơn giản: Một công ty muốn xây dựng mô hình dự đoán từ bàn phím ảo trên điện thoại thông minh. Theo cách truyền thống, họ phải thu thập toàn bộ lịch sử gõ phím của người dùng về máy chủ trung tâm. Với Federated Learning, quy trình diễn ra hoàn toàn khác:
Bước 1 – Khởi tạo: Mô hình AI ban đầu được tải xuống hàng triệu điện thoại của người dùng.
Bước 2 – Huấn luyện cục bộ: Mỗi chiếc điện thoại tự học từ dữ liệu gõ phím của chính người dùng đó. Dữ liệu không bao giờ rời khỏi thiết bị.
Bước 3 – Gửi bản cập nhật: Thay vì gửi dữ liệu, điện thoại chỉ gửi lại các “bản cập nhật” (gradients) – tức là những thay đổi về trọng số của mô hình sau khi học.
Bước 4 – Tổng hợp: Máy chủ trung tâm nhận hàng triệu bản cập nhật từ các thiết bị, tổng hợp chúng lại để cải thiện mô hình gốc.
Bước 5 – Lặp lại: Mô hình mới, tốt hơn, lại được gửi xuống các thiết bị cho vòng huấn luyện tiếp theo.
Quy trình này đảm bảo dữ liệu cá nhân nhạy cảm (tin nhắn, thói quen, vị trí) được bảo vệ tuyệt đối, trong khi mô hình AI vẫn được cải thiện liên tục nhờ học từ dữ liệu phân tán.
Phân loại Federated Learning: Kiến trúc và đặc điểm
Không phải mọi hệ thống Federated Learning đều giống nhau. Tùy vào cách bố trí dữ liệu và kiến trúc mạng, chúng ta có ba loại chính:
Loại hình
Đặc điểm dữ liệu
Ví dụ ứng dụng
Federated Learning tập trung (Centralized)
Dữ liệu được phân chia ngẫu nhiên trên các client, có thể không đồng nhất về số lượng mẫu.
Dự đoán từ bàn phím ảo, gợi ý ứng dụng trên điện thoại.
Federated Learning phân tán (Decentralized)
Không có máy chủ trung tâm. Các client trao đổi trực tiếp với nhau theo cấu trúc mạng ngang hàng (P2P).
Mạng lưới thiết bị IoT trong nhà máy thông minh, nơi không có kết nối internet ổn định đến trung tâm.
Federated Learning theo chiều dọc (Vertical)
Các client có cùng tập người dùng nhưng khác nhau về thuộc tính (features). Ví dụ: Ngân hàng A có thông tin giao dịch, Bệnh viện B có hồ sơ sức khỏe của cùng một người.
Hợp tác giữa các tổ chức tài chính và y tế để phát hiện gian lận bảo hiểm mà không vi phạm quyền riêng tư.
Federated Learning theo chiều ngang (Horizontal)
Các client có cùng thuộc tính (features) nhưng khác nhau về tập người dùng. Đây là dạng phổ biến nhất.
Huấn luyện mô hình nhận diện giọng nói từ dữ liệu của người dùng trên toàn thế giới.
Lợi ích vượt trội của Federated Learning so với phương pháp truyền thống
Việc hiểu Federated Learning là gì sẽ không đầy đủ nếu không phân tích những lợi ích then chốt mà nó mang lại:
Bảo vệ quyền riêng tư tuyệt đối
Đây là lợi ích cốt lõi. Dữ liệu thô không bao giờ rời khỏi thiết bị hoặc máy chủ cục bộ. Các bản cập nhật được gửi đi thường được mã hóa hoặc nhiễu hóa thêm bằng kỹ thuật Differential Privacy, khiến việc tái tạo dữ liệu gốc gần như bất khả thi. Điều này giúp doanh nghiệp tuân thủ nghiêm ngặt các quy định pháp lý như GDPR, CCPA hay Luật An ninh mạng Việt Nam.
Giảm chi phí băng thông và lưu trữ
Thay vì tải lên hàng terabyte dữ liệu thô, Federated Learning chỉ truyền tải các bản cập nhật mô hình có kích thước rất nhỏ (thường chỉ vài kilobyte đến vài megabyte). Điều này giảm tải đáng kể cho hạ tầng mạng và chi phí lưu trữ đám mây.
Cá nhân hóa thông minh hơn
Mô hình được huấn luyện trực tiếp trên dữ liệu của từng người dùng, do đó có khả năng thích ứng cao với hành vi và sở thích riêng. Ví dụ, tính năng gợi ý từ trên bàn phím Google Gboard sử dụng Federated Learning để học cách gõ của từng người, mang lại trải nghiệm chính xác hơn nhiều so với mô hình chung chung.
Tận dụng dữ liệu nhạy cảm
Nhiều lĩnh vực như y tế, tài chính sở hữu kho dữ liệu vô giá nhưng không thể chia sẻ do tính bảo mật. Federated Learning cho phép các bệnh viện khác nhau cùng huấn luyện một mô hình chẩn đoán bệnh mà không cần tiết lộ hồ sơ bệnh nhân.
Hạn chế và thách thức khi triển khai Federated Learning
Mặc dù là công nghệ đầy hứa hẹn, Federated Learning là gì nếu chỉ nhìn vào mặt tích cực? Nó cũng đối mặt với những thách thức không nhỏ:
Chi phí giao tiếp cao: Mặc dù giảm băng thông dữ liệu, nhưng số lượng vòng lặp giao tiếp giữa client và server có thể rất lớn, đặc biệt khi mạng không ổn định hoặc số lượng client lên đến hàng triệu.
Dữ liệu không đồng nhất (Non-IID): Dữ liệu trên mỗi client thường rất khác nhau. Một người dùng có thể gõ tiếng Anh, người khác gõ tiếng Việt. Điều này khiến mô hình khó hội tụ và giảm độ chính xác.
Rủi ro bảo mật từ bản cập nhật: Kẻ tấn công có thể phân tích các bản cập nhật (gradients) để suy luận ra thông tin nhạy cảm. Kỹ thuật tấn công “inversion attack” có thể tái tạo một phần dữ liệu huấn luyện từ gradients.
Khó khăn trong việc đồng bộ: Các thiết bị client có thể không đồng đều về năng lực tính toán, pin, hoặc kết nối mạng. Một số client có thể “chết” giữa chừng, ảnh hưởng đến toàn bộ quá trình huấn luyện.
So sánh Federated Learning với các phương pháp học máy khác
Để có cái nhìn toàn diện về Federated Learning là gì, cần đặt nó lên bàn cân so sánh với các phương pháp phổ biến:
Tiêu chí
Federated Learning
Học máy tập trung (Centralized ML)
Học máy cục bộ (Local ML)
Vị trí dữ liệu
Phân tán trên client
Tập trung tại server
Trên từng client riêng lẻ
Quyền riêng tư
Cao (dữ liệu không rời client)
Thấp (dữ liệu tập trung dễ bị rò rỉ)
Rất cao (dữ liệu hoàn toàn cục bộ)
Chất lượng mô hình
Cao (học từ nhiều nguồn)
Rất cao (dữ liệu lớn, đồng nhất)
Thấp (chỉ học từ một nguồn nhỏ)
Chi phí hạ tầng
Trung bình (cần server tổng hợp)
Cao (cần server mạnh, lưu trữ lớn)
Thấp (chạy trên thiết bị)
Khả năng mở rộng
Rất tốt (hàng triệu client)
Khó khăn khi dữ liệu quá lớn
Không mở rộng được
Ứng dụng thực tế của Federated Learning trong đời sống
Công nghệ này không chỉ nằm trên lý thuyết. Nhiều “ông lớn” công nghệ đã và đang ứng dụng Federated Learning là gì vào sản phẩm của họ:
Google Gboard và trợ lý ảo
Google là một trong những công ty tiên phong. Tính năng gợi ý từ thông minh trên bàn phím Gboard sử dụng Federated Learning để học từ thói quen gõ của từng người dùng mà không thu thập dữ liệu nhạy cảm. Kết quả là độ chính xác của các gợi ý tăng lên đáng kể qua từng phiên bản.
Apple và tính năng QuickType
Apple cũng tích hợp Federated Learning vào iOS để cải thiện tính năng QuickType (gợi ý từ) và Siri. Dữ liệu được xử lý hoàn toàn trên thiết bị, chỉ gửi các bản cập nhật ẩn danh về máy chủ của Apple.
Y tế: Chẩn đoán bệnh từ nhiều bệnh viện
Các tập đoàn như NVIDIA và Intel đang phát triển nền tảng Federated Learning cho lĩnh vực y tế. Các bệnh viện có thể cùng huấn luyện mô hình AI phát hiện khối u trên ảnh X-quang hoặc MRI mà không cần chia sẻ hình ảnh bệnh nhân ra bên ngoài. Một nghiên cứu năm 2021 cho thấy mô hình được huấn luyện bằng Federated Learning đạt độ chính xác tương đương 97% so với mô hình tập trung, trong khi vẫn đảm bảo quyền riêng tư.
Tài chính: Phát hiện gian lận giao dịch
Các ngân hàng có thể hợp tác xây dựng mô hình phát hiện giao dịch bất thường mà không tiết lộ thông tin khách hàng. Mỗi ngân hàng giữ dữ liệu giao dịch của mình, chỉ chia sẻ “bài học” (bản cập nhật mô hình) với các ngân hàng khác.
Sai lầm thường gặp khi triển khai Federated Learning
Nhiều đội ngũ kỹ thuật khi mới tìm hiểu Federated Learning là gì thường mắc phải những sai lầm sau:
Bỏ qua vấn đề dữ liệu không đồng nhất: Áp dụng thuật toán FedAvg (Federated Averaging) tiêu chuẩn cho dữ liệu Non-IID có thể khiến mô hình không hội tụ hoặc giảm độ chính xác nghiêm trọng. Cần sử dụng các biến thể như FedProx hoặc SCAFFOLD.
Không mã hóa bản cập nhật: Gửi gradients “trần” qua mạng là một lỗ hổng bảo mật lớn. Luôn kết hợp với mã hóa đồng cấu (Homomorphic Encryption) hoặc Secure Multi-Party Computation.
Chọn sai số lượng client mỗi vòng: Chọn quá ít client dẫn đến mô hình thiếu đa dạng, chọn quá nhiều gây quá tải server và lãng phí tài nguyên. Tỷ lệ 10-20% tổng số client thường là điểm cân bằng tốt.
Thiếu cơ chế chịu lỗi: Không xử lý trường hợp client ngắt kết nối giữa chừng. Cần có cơ chế timeout và loại bỏ client không phản hồi.
Lưu ý quan trọng khi áp dụng Federated Learning
Để triển khai thành công, doanh nghiệp cần ghi nhớ những điểm sau:
Đánh giá chi phí – lợi ích: Federated Learning không phải lúc nào cũng là giải pháp tốt nhất. Nếu dữ liệu không quá nhạy cảm và hạ tầng tập trung đủ mạnh, phương pháp truyền thống vẫn hiệu quả hơn.
Kết hợp nhiều lớp bảo vệ: Sử dụng kết hợp Federated Learning với Differential Privacy và mã hóa để tạo ra hệ thống bảo mật nhiều lớp.
Kiểm thử trên môi trường mô phỏng: Trước khi triển khai thực tế, hãy xây dựng môi trường mô phỏng với dữ liệu giả để kiểm tra độ hội tụ và hiệu suất của mô hình.
Tuân thủ pháp lý: Dù dữ liệu không rời client, việc thu thập bản cập nhật vẫn có thể bị coi là xử lý dữ liệu. Cần có sự đồng ý rõ ràng từ người dùng và tư vấn pháp lý chuyên sâu.
Câu hỏi thường gặp về Federated Learning
Federated Learning có thực sự bảo vệ quyền riêng tư 100% không?
Không có hệ thống nào bảo vệ tuyệt đối. Federated Learning giảm thiểu rủi ro rò rỉ dữ liệu thô, nhưng vẫn tồn tại nguy cơ tấn công từ gradients. Kết hợp với Differential Privacy giúp tăng cường bảo mật đáng kể.
Federated Learning khác gì với học máy phân tán (Distributed Learning)?
Trong học máy phân tán, dữ liệu được chia nhỏ và gửi đến các node tính toán trong một trung tâm dữ liệu. Mục tiêu là tăng tốc độ huấn luyện. Trong Federated Learning, dữ liệu nằm rải rác trên các thiết bị biên, mục tiêu chính là bảo vệ quyền riêng tư.
Có thể áp dụng Federated Learning cho doanh nghiệp nhỏ không?
Hoàn toàn có thể. Các framework mã nguồn mở như TensorFlow Federated (Google), PySyft (OpenMined) hay FATE (WeBank) cho phép doanh nghiệp nhỏ triển khai thử nghiệm với chi phí thấp. Tuy nhiên, cần có đội ngũ kỹ thuật am hiểu về machine learning và bảo mật.
Federated Learning có làm chậm thiết bị người dùng không?
Các thuật toán được tối ưu để chạy ngầm, chỉ sử dụng tài nguyên khi thiết bị rảnh rỗi, đang sạc và kết nối WiFi. Google ước tính tác động đến pin và hiệu năng là không đáng kể (dưới 1%).
Kết luận
Federated Learning là gì? Đó không chỉ là một thuật ngữ kỹ thuật, mà là một triết lý mới về cách chúng ta xây dựng trí tuệ nhân tạo trong thời đại mà quyền riêng tư là vàng. Nó cho phép khai thác sức mạnh của dữ liệu phân tán mà không đánh đổi sự an toàn của người dùng. Mặc dù còn tồn tại những thách thức về kỹ thuật và chi phí, Federated Learning đang dần trở thành tiêu chuẩn cho các ứng dụng AI nhạy cảm về dữ liệu. Các doanh nghiệp, từ gã khổng lồ công nghệ đến startup y tế, đều đang tìm cách tích hợp công nghệ này để vừa đổi mới sáng tạo, vừa xây dựng lòng tin với khách hàng. Nếu bạn đang tìm kiếm một hướng đi bền vững cho AI trong tương lai, Federated Learning chính là câu trả lời bạn cần khám phá ngay hôm nay.