Trong thời đại số hóa, mỗi giây trôi qua đều tạo ra một lượng thông tin khổng lồ từ các thiết bị di động, mạng xã hội, cảm biến IoT và giao dịch trực tuyến. Big Data không chỉ là một thuật ngữ công nghệ mà đã trở thành tài sản chiến lược của mọi tổ chức. Hiểu rõ Big Data là gì giúp doanh nghiệp khai thác sức mạnh từ dữ liệu để đưa ra quyết định chính xác, dự báo xu hướng và tối ưu hóa vận hành. Bài viết này sẽ giải thích chi tiết từ khái niệm cơ bản đến ứng dụng thực tế, giúp bạn nắm vững toàn bộ kiến thức về dữ liệu lớn.
Big Data, hay dữ liệu lớn, là tập hợp dữ liệu có khối lượng khổng lồ, tốc độ tăng trưởng nhanh và đa dạng về định dạng, vượt quá khả năng xử lý của các công cụ quản lý dữ liệu truyền thống. Khái niệm này không chỉ đề cập đến kích thước dữ liệu mà còn bao gồm cách thức thu thập, lưu trữ, phân tích và khai thác giá trị từ chúng.
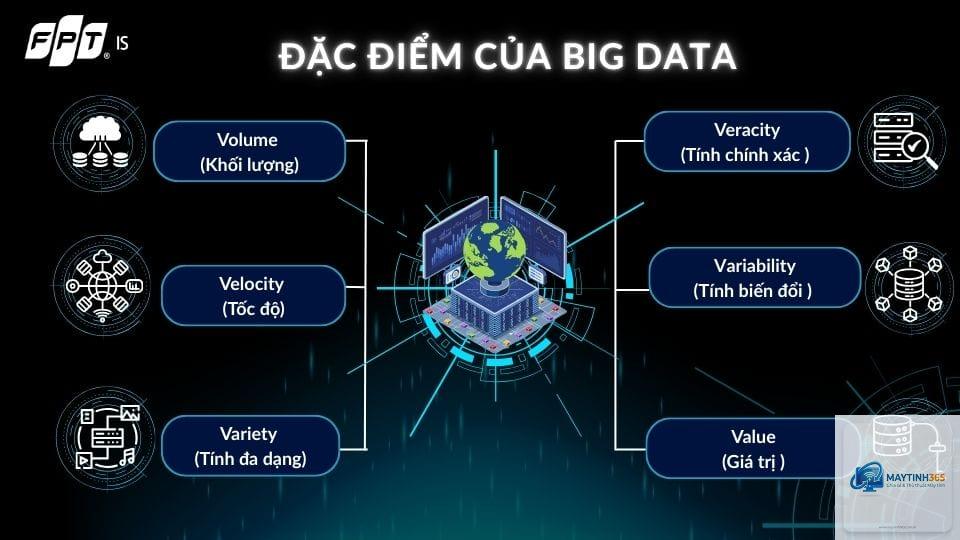
Big Data thường được mô tả qua 5 đặc tính cốt lõi, gọi là 5V: Volume (Khối lượng), Velocity (Tốc độ), Variety (Đa dạng), Veracity (Tính xác thực) và Value (Giá trị). Những đặc tính này giúp phân biệt dữ liệu lớn với dữ liệu thông thường.
Volume – Khối lượng dữ liệu khổng lồ
Volume đề cập đến lượng dữ liệu được tạo ra mỗi ngày. Theo thống kê, mỗi ngày thế giới tạo ra khoảng 2,5 quintillion byte dữ liệu. Các doanh nghiệp lớn như Google, Facebook hay Amazon xử lý hàng petabyte dữ liệu mỗi ngày. Khối lượng này đến từ nhiều nguồn khác nhau như nhật ký web, giao dịch tài chính, video giám sát và dữ liệu cảm biến.
Velocity – Tốc độ xử lý dữ liệu
Velocity là tốc độ dữ liệu được tạo ra và cần được xử lý. Trong nhiều trường hợp, dữ liệu phải được phân tích theo thời gian thực để đưa ra quyết định ngay lập tức. Ví dụ, hệ thống giao dịch chứng khoán xử lý hàng triệu giao dịch mỗi giây, hay các nền tảng streaming như Netflix phân tích hành vi người dùng để đề xuất nội dung tức thì.
Variety chỉ sự đa dạng về định dạng dữ liệu. Dữ liệu lớn bao gồm ba loại chính:
Dữ liệu có cấu trúc: dữ liệu trong bảng, cơ sở dữ liệu quan hệ
Dữ liệu bán cấu trúc: file JSON, XML, log file
Dữ liệu phi cấu trúc: văn bản, hình ảnh, video, âm thanh, bài đăng mạng xã hội
Veracity – Độ tin cậy của dữ liệu
Veracity đề cập đến chất lượng và độ chính xác của dữ liệu. Dữ liệu từ nhiều nguồn khác nhau có thể chứa nhiễu, sai lệch hoặc không nhất quán. Xử lý dữ liệu không đảm bảo độ tin cậy có thể dẫn đến những phân tích sai lầm và quyết định tồi tệ.
Value – Giá trị kinh doanh
Value là mục tiêu cuối cùng của Big Data. Dữ liệu chỉ có ý nghĩa khi được chuyển hóa thành giá trị thực tế như tăng doanh thu, giảm chi phí, cải thiện trải nghiệm khách hàng hoặc phát hiện cơ hội kinh doanh mới.
Kiến trúc và thành phần của hệ thống Big Data
Một hệ thống Big Data hoàn chỉnh bao gồm nhiều lớp kiến trúc khác nhau, từ thu thập dữ liệu đến trực quan hóa kết quả. Hiểu rõ các thành phần này giúp doanh nghiệp xây dựng hạ tầng dữ liệu hiệu quả.
Lớp thu thập dữ liệu
Dữ liệu được thu thập từ nhiều nguồn khác nhau thông qua các công cụ như Apache Kafka, Flume hay các API. Lớp này đảm bảo dữ liệu được nhập vào hệ thống một cách liên tục và đáng tin cậy.
Lớp lưu trữ
Dữ liệu lớn yêu cầu hệ thống lưu trữ phân tán có khả năng mở rộng. Hadoop Distributed File System (HDFS) và Amazon S3 là hai giải pháp phổ biến. Các cơ sở dữ liệu NoSQL như MongoDB, Cassandra cũng được sử dụng để lưu trữ dữ liệu phi cấu trúc.
Lớp xử lý và phân tích
Lớp này bao gồm các công cụ xử lý dữ liệu như Apache Spark, Hadoop MapReduce và Apache Flink. Các công cụ này cho phép xử lý dữ liệu theo batch hoặc real-time, thực hiện các tác vụ như làm sạch dữ liệu, chuyển đổi và phân tích thống kê.
Lớp truy vấn và trực quan hóa
Sau khi xử lý, dữ liệu được truy vấn thông qua các công cụ như Hive, Presto hay Apache Drill. Kết quả phân tích được trực quan hóa bằng các nền tảng như Tableau, Power BI hoặc các thư viện Python như Matplotlib, Seaborn.
Phân loại Big Data
Dữ liệu lớn có thể được phân loại theo nhiều tiêu chí khác nhau.
Bước 1: Thu thập dữ liệu
Dữ liệu được thu thập từ nhiều nguồn khác nhau như website, ứng dụng di động, cảm biến IoT, mạng xã hội và hệ thống CRM. Các công cụ như Apache Kafka, Flume và Logstash giúp thu thập dữ liệu theo thời gian thực.
Bước 2: Lưu trữ dữ liệu
Dữ liệu sau khi thu thập được lưu trữ trong các hệ thống phân tán như HDFS, Amazon S3 hoặc Google Cloud Storage. Lựa chọn giải pháp lưu trữ phụ thuộc vào khối lượng dữ liệu, yêu cầu về tốc độ truy xuất và ngân sách.
Bước 3: Xử lý và làm sạch dữ liệu
Dữ liệu thô thường chứa nhiễu, trùng lặp hoặc thiếu giá trị. Bước này bao gồm loại bỏ dữ liệu không hợp lệ, chuẩn hóa định dạng và xử lý giá trị khuyết thiếu. Apache Spark và Hadoop MapReduce là hai công cụ phổ biến cho giai đoạn này.
Bước 4: Phân tích dữ liệu
Dữ liệu sạch được phân tích bằng các thuật toán thống kê, machine learning hoặc deep learning. Các kỹ thuật phân tích bao gồm phân tích mô tả, phân tích chẩn đoán, phân tích dự báo và phân tích chỉ định.
Bước 5: Trực quan hóa và ra quyết định
Kết quả phân tích được trình bày dưới dạng biểu đồ, dashboard hoặc báo cáo. Các nhà quản lý dựa vào những thông tin này để đưa ra quyết định kinh doanh chiến lược.
Lợi ích của Big Data đối với doanh nghiệp
Big Data mang lại nhiều lợi ích thiết thực cho doanh nghiệp ở mọi quy mô.
Chi phí đầu tư cao
Hạ tầng Big Data yêu cầu đầu tư lớn vào phần cứng, phần mềm và nhân lực. Chi phí cho hệ thống lưu trữ phân tán, công cụ xử lý và đội ngũ kỹ sư dữ liệu có thể lên đến hàng triệu đô la.
Vấn đề bảo mật và quyền riêng tư
Dữ liệu lớn thường chứa thông tin nhạy cảm của khách hàng. Việc tuân thủ các quy định như GDPR, CCPA và bảo vệ dữ liệu khỏi các cuộc tấn công mạng là thách thức lớn.
Thiếu nhân lực chất lượng cao
Nhu cầu về data scientist, data engineer và data analyst đang tăng cao nhưng nguồn cung nhân lực có kỹ năng phù hợp còn hạn chế. Điều này dẫn đến chi phí tuyển dụng và đào tạo cao.
Chất lượng dữ liệu không đồng nhất
Dữ liệu từ nhiều nguồn khác nhau thường không nhất quán về định dạng, độ chính xác và độ tin cậy. Việc làm sạch và chuẩn hóa dữ liệu chiếm đến 80% thời gian của các dự án Big Data.
Ứng dụng thực tế của Big Data trong các ngành
Big Data đã và đang thay đổi cách vận hành của nhiều ngành công nghiệp. JPMorgan Chase xử lý hàng triệu giao dịch mỗi ngày bằng hệ thống phân tích dữ liệu lớn.
Ngành y tế
Big Data giúp phân tích hồ sơ bệnh án điện tử, dự đoán dịch bệnh và cá nhân hóa phác đồ điều trị. Các bệnh viện sử dụng dữ liệu từ thiết bị đeo thông minh để theo dõi sức khỏe bệnh nhân từ xa.
Ngành bán lẻ
Walmart và Amazon sử dụng Big Data để dự báo nhu cầu hàng hóa, tối ưu giá cả và đề xuất sản phẩm dựa trên lịch sử mua sắm. Hệ thống quản lý tồn kho thông minh giúp giảm thiểu hàng tồn kho và tăng doanh thu.
Ngành sản xuất
Các nhà máy thông minh sử dụng cảm biến IoT và phân tích dữ liệu để bảo trì dự đoán, giảm thời gian ngừng máy và tối ưu hóa quy trình sản xuất. General Electric tiết kiệm hàng triệu đô la nhờ phân tích dữ liệu từ động cơ máy bay.
Ngành viễn thông
Các nhà mạng sử dụng Big Data để phân tích lưu lượng mạng, dự đoán sự cố và cá nhân hóa gói cước. Họ cũng sử dụng dữ liệu để giảm tỷ lệ rời bỏ khách hàng bằng cách phát hiện sớm các dấu hiệu không hài lòng.
Sai lầm thường gặp khi triển khai Big Data
Nhiều doanh nghiệp thất bại trong việc khai thác Big Data do những sai lầm phổ biến sau:
Thu thập dữ liệu không có mục tiêu: Thu thập càng nhiều dữ liệu càng tốt mà không xác định rõ vấn đề cần giải quyết
Bỏ qua chất lượng dữ liệu: Đầu tư vào công nghệ nhưng không chú trọng làm sạch và chuẩn hóa dữ liệu
Thiếu sự hỗ trợ từ lãnh đạo: Dự án Big Data không được cấp quản lý cấp cao ủng hộ và cấp đủ nguồn lực
Không có chiến lược rõ ràng: Triển khai công nghệ mà không có kế hoạch kinh doanh cụ thể
Bỏ qua vấn đề bảo mật: Không tuân thủ các quy định về quyền riêng tư dữ liệu ngay từ đầu
Lưu ý quan trọng khi bắt đầu với Big Data
Để triển khai Big Data thành công, doanh nghiệp cần lưu ý những điểm sau:
Bắt đầu với một vấn đề kinh doanh cụ thể, không chạy theo công nghệ
Đầu tư vào đào tạo nhân lực và xây dựng văn hóa dữ liệu trong tổ chức
Chọn giải pháp phù hợp với quy mô và ngân sách, có thể bắt đầu với các công cụ mã nguồn mở
Đảm bảo tuân thủ các quy định về bảo vệ dữ liệu ngay từ giai đoạn thiết kế
Xây dựng hệ thống có khả năng mở rộng để đáp ứng nhu cầu tương lai
Big Data khác dữ liệu thông thường ở 5 đặc tính: khối lượng lớn, tốc độ xử lý nhanh, đa dạng về định dạng, độ tin cậy thấp hơn và yêu cầu công nghệ đặc thù để khai thác giá trị. Dữ liệu thông thường thường được xử lý bằng các công cụ SQL truyền thống, trong khi Big Data yêu cầu hệ thống phân tán như Hadoop hay Spark.
Big Data có cần thiết cho doanh nghiệp nhỏ không?
Có, Big Data không chỉ dành cho tập đoàn lớn. Doanh nghiệp nhỏ có thể tận dụng các giải pháp đám mây như Google BigQuery, Amazon Redshift với chi phí thấp để phân tích dữ liệu khách hàng, tối ưu marketing và cải thiện dịch vụ.
Học Big Data cần những kỹ năng gì?
Để làm việc với Big Data, bạn cần kiến thức về lập trình Python hoặc Java, hiểu về cơ sở dữ liệu SQL và NoSQL, thành thạo các công cụ như Hadoop, Spark, và có kiến thức về thống kê, machine learning. Kỹ năng tư duy phân tích và giải quyết vấn đề cũng rất quan trọng.
Công cụ nào phổ biến nhất trong Big Data?
Các công cụ phổ biến bao gồm Apache Hadoop cho lưu trữ và xử lý phân tán, Apache Spark cho xử lý nhanh, Apache Kafka cho thu thập dữ liệu thời gian thực, và các cơ sở dữ liệu NoSQL như MongoDB, Cassandra. Trên nền tảng đám mây, AWS, Google Cloud và Azure cung cấp các dịch vụ Big Data tích hợp.
Big Data và AI có mối quan hệ mật thiết. Dữ liệu lớn cung cấp nguyên liệu đầu vào để huấn luyện các mô hình machine learning và deep learning. Ngược lại, AI giúp tự động hóa quá trình phân tích và khai thác giá trị từ Big Data một cách hiệu quả hơn.
Kết luận
Big Data không chỉ là một xu hướng công nghệ nhất thời mà đã trở thành nền tảng cho sự phát triển bền vững của doanh nghiệp trong kỷ nguyên số. Hiểu rõ Big Data là gì, từ khái niệm 5V đến kiến trúc hệ thống và ứng dụng thực tế, giúp tổ chức xây dựng chiến lược dữ liệu hiệu quả. Mặc dù đối mặt với nhiều thách thức về chi phí, nhân lực và bảo mật, những lợi ích mà Big Data mang lại là không thể phủ nhận. Bắt đầu từ những bước nhỏ, tập trung vào vấn đề kinh doanh cụ thể và đầu tư đúng đắn vào công nghệ và con người sẽ giúp doanh nghiệp khai thác tối đa sức mạnh của dữ liệu lớn.