Trong kỷ nguyên bùng nổ của trí tuệ nhân tạo và học máy, một thuật ngữ ngày càng xuất hiện dày đặc trong giới công nghệ là Vector Database. Không chỉ đơn thuần là một cơ sở dữ liệu mới, Vector Database đang âm thầm thay đổi cách chúng ta lưu trữ, tìm kiếm và xử lý dữ liệu phi cấu trúc như văn bản, hình ảnh, âm thanh và video. Bài viết này sẽ đi sâu vào khái niệm Vector Database là gì, cách thức hoạt động, lợi ích vượt trội và những ứng dụng thực tế đang định hình tương lai.
Vector Database là gì? Định nghĩa và bản chất cốt lõi
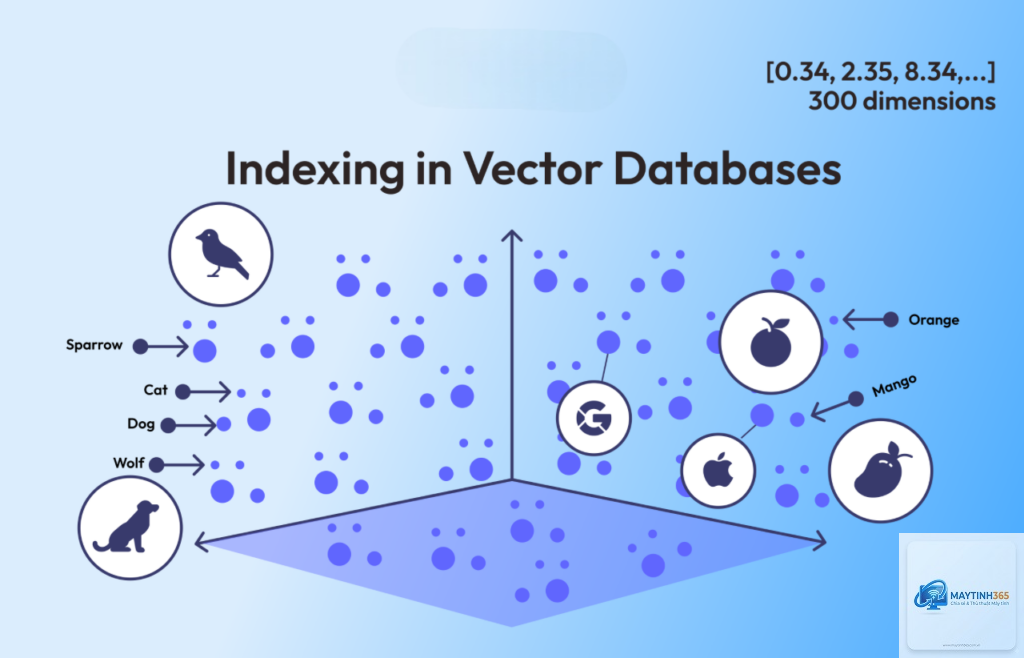
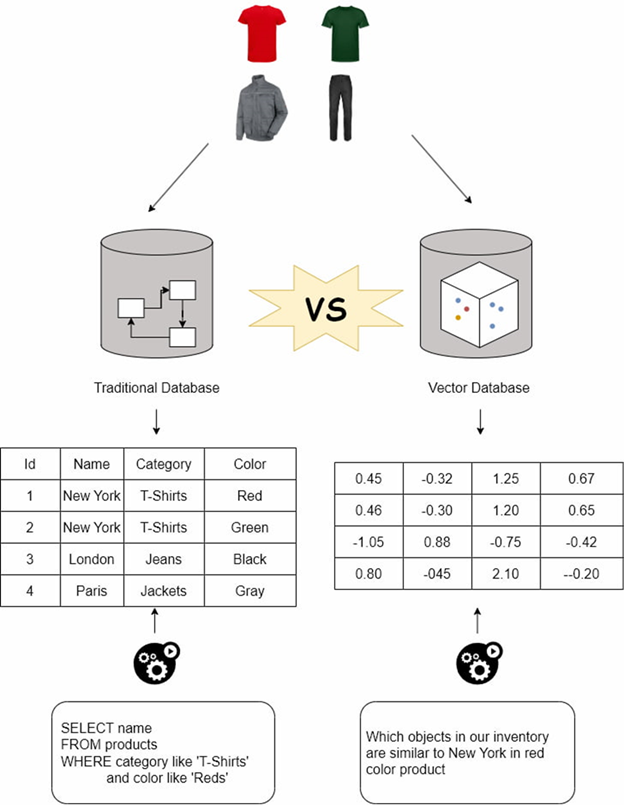
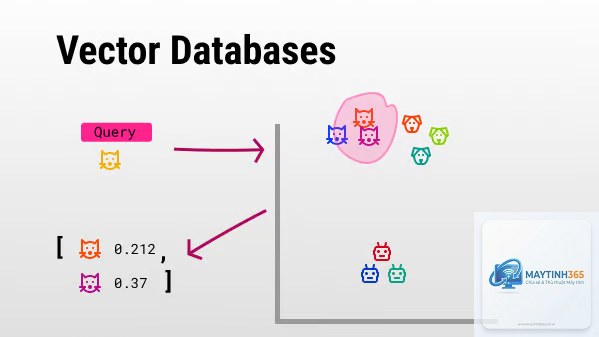
Vector Database, hay cơ sở dữ liệu vector, là một loại cơ sở dữ liệu được thiết kế đặc biệt để lưu trữ, quản lý và truy vấn các vector nhúng (embeddings). Khác với cơ sở dữ liệu quan hệ truyền thống lưu trữ dữ liệu dưới dạng hàng và cột với các kiểu dữ liệu cứng nhắc, Vector Database hoạt động dựa trên các biểu diễn toán học của dữ liệu trong không gian đa chiều.
Bản chất của Vector Database nằm ở khả năng chuyển đổi dữ liệu phi cấu trúc thành các vector số học. Mỗi vector là một mảng các số thực, đại diện cho các đặc trưng ngữ nghĩa hoặc ngữ cảnh của dữ liệu gốc. Ví dụ, một câu văn “chú mèo đang ngủ” sẽ được chuyển thành một vector có hàng trăm hoặc hàng nghìn chiều, nơi mỗi chiều mã hóa một khía cạnh ngữ nghĩa nhất định.
Sự khác biệt giữa Vector Database và cơ sở dữ liệu truyền thống
So khớp chính xác (exact match) dựa trên điều kiện
Tìm kiếm tương tự (similarity search) dựa trên khoảng cách vector
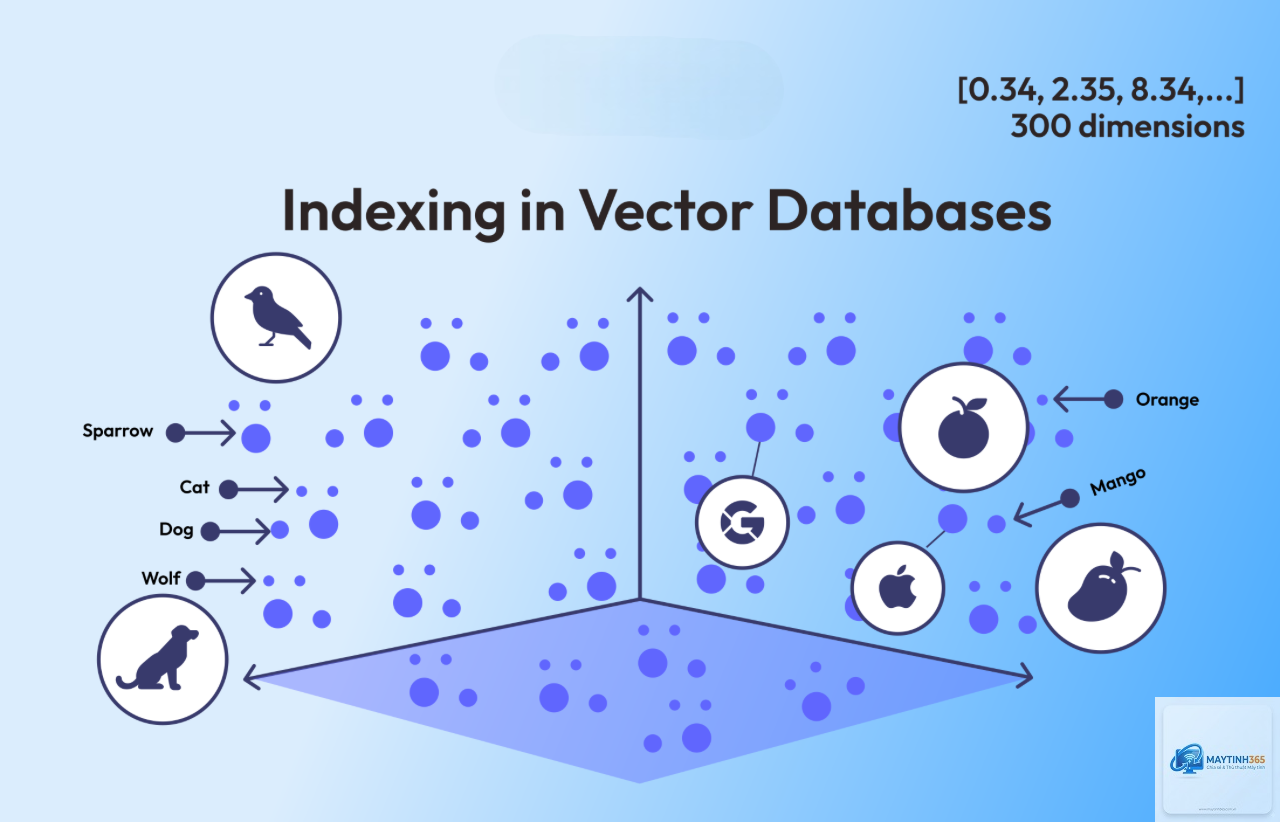
Chỉ mục
B-tree, Hash index
HNSW, IVF, PQ (các chỉ mục vector chuyên dụng)
Hiệu suất với dữ liệu lớn
Giảm dần khi dữ liệu tăng và truy vấn phức tạp
Duy trì hiệu suất cao nhờ tối ưu hóa không gian vector
Ứng dụng chính
Quản lý giao dịch, báo cáo, hệ thống ERP
AI, Machine Learning, hệ thống gợi ý, tìm kiếm ngữ nghĩa
Cách thức hoạt động của Vector Database
Quy trình hoạt động của Vector Database bao gồm ba bước chính: tạo vector nhúng, lưu trữ và đánh chỉ mục, và truy vấn tìm kiếm tương tự.
Bước 1: Tạo vector nhúng (Embedding Generation)
Trước khi dữ liệu được đưa vào Vector Database, nó phải trải qua quá trình chuyển đổi thành vector thông qua các mô hình học máy chuyên dụng. Các mô hình phổ biến bao gồm Word2Vec, GloVe cho văn bản, ResNet cho hình ảnh, hoặc các mô hình ngôn ngữ lớn như BERT, GPT. Mỗi mô hình sẽ ánh xạ dữ liệu đầu vào thành một vector có số chiều cố định, thường từ 128 đến 4096 chiều.
Ví dụ thực tế: Khi bạn tải lên một bức ảnh chụp cảnh biển, mô hình ResNet sẽ phân tích các đặc trưng như màu sắc, đường nét, hình dạng và tạo ra một vector đại diện. Vector này sẽ gần với các vector của những bức ảnh biển khác và xa với vector của ảnh chụp núi rừng.
Bước 2: Lưu trữ và đánh chỉ mục vector
Sau khi có vector, Vector Database sẽ lưu trữ chúng cùng với metadata (dữ liệu gốc) trong một cấu trúc dữ liệu đặc biệt. Điểm mấu chốt là các chỉ mục vector được tối ưu hóa để tìm kiếm láng giềng gần nhất (Approximate Nearest Neighbor – ANN) thay vì tìm kiếm chính xác. Các thuật toán ANN phổ biến bao gồm:
HNSW (Hierarchical Navigable Small World): Xây dựng cấu trúc đồ thị phân cấp, cho phép tìm kiếm nhanh với độ chính xác cao.
IVF (Inverted File Index): Phân cụm vector thành các nhóm, giúp giảm không gian tìm kiếm.
PQ (Product Quantization): Nén vector để giảm bộ nhớ lưu trữ và tăng tốc độ truy vấn.
Bước 3: Truy vấn tìm kiếm tương tự
Khi người dùng thực hiện truy vấn, Vector Database sẽ chuyển đổi truy vấn đó thành vector bằng cùng mô hình nhúng đã sử dụng. Sau đó, hệ thống tính toán khoảng cách giữa vector truy vấn và tất cả các vector trong cơ sở dữ liệu, thường sử dụng các phép đo như:
Cosine similarity: Đo góc giữa hai vector, phù hợp cho văn bản và ngữ nghĩa.
Euclidean distance: Khoảng cách hình học trực tiếp, thích hợp cho dữ liệu số.
Dot product: Tích vô hướng, thường dùng trong các hệ thống gợi ý.
Kết quả trả về là danh sách các vector có khoảng cách gần nhất với vector truy vấn, kèm theo metadata tương ứng.
Lợi ích vượt trội của Vector Database
Vector Database mang lại nhiều lợi ích mà cơ sở dữ liệu truyền thống không thể đáp ứng được, đặc biệt trong bối cảnh dữ liệu phi cấu trúc ngày càng chiếm ưu thế.
Tìm kiếm ngữ nghĩa thông minh
Thay vì tìm kiếm dựa trên từ khóa chính xác, Vector Database hiểu được ngữ nghĩa và ngữ cảnh của dữ liệu. Ví dụ, tìm kiếm “xe hơi thể thao” có thể trả về kết quả về “Ferrari” hoặc “Porsche” ngay cả khi các từ này không xuất hiện trong truy vấn. Điều này tạo ra trải nghiệm tìm kiếm tự nhiên và chính xác hơn nhiều.
Hiệu suất vượt trội với dữ liệu quy mô lớn
Vector Database được tối ưu hóa để xử lý hàng tỷ vector chỉ trong mili giây. Các kỹ thuật như phân cụm, nén vector và tìm kiếm xấp xỉ cho phép hệ thống duy trì tốc độ truy vấn ổn định ngay cả khi khối lượng dữ liệu tăng lên theo cấp số nhân. Một số hệ thống có thể xử lý hơn 10.000 truy vấn mỗi giây trên cơ sở dữ liệu 1 tỷ vector.
Hỗ trợ đa dạng kiểu dữ liệu
Một Vector Database duy nhất có thể lưu trữ và truy vấn đồng thời văn bản, hình ảnh, âm thanh và video. Điều này đặc biệt hữu ích cho các ứng dụng đa phương thức (multimodal) như tìm kiếm sản phẩm bằng hình ảnh hoặc hệ thống gợi ý nội dung đa dạng.
Khả năng mở rộng linh hoạt
Hầu hết các Vector Database hiện đại đều hỗ trợ kiến trúc phân tán, cho phép mở rộng theo chiều ngang bằng cách thêm nhiều node. Điều này giúp doanh nghiệp dễ dàng mở rộng quy mô mà không cần thay đổi kiến trúc hệ thống.
Hạn chế và thách thức của Vector Database
Mặc dù có nhiều ưu điểm, Vector Database cũng đối mặt với một số thách thức cần cân nhắc.
Độ chính xác phụ thuộc vào mô hình nhúng
Chất lượng của vector nhúng quyết định trực tiếp đến độ chính xác của kết quả truy vấn. Nếu mô hình nhúng không được huấn luyện tốt hoặc không phù hợp với lĩnh vực dữ liệu, kết quả tìm kiếm có thể sai lệch. Việc lựa chọn và tinh chỉnh mô hình nhúng đòi hỏi chuyên môn sâu về machine learning.
Yêu cầu tài nguyên tính toán cao
Việc tạo vector nhúng và duy trì chỉ mục vector đòi hỏi tài nguyên CPU và RAM đáng kể. Đặc biệt, các thuật toán HNSW yêu cầu bộ nhớ lớn để lưu trữ cấu trúc đồ thị. Điều này có thể làm tăng chi phí vận hành so với cơ sở dữ liệu truyền thống.
Khi dữ liệu gốc thay đổi, vector nhúng cũng cần được cập nhật. Quá trình này có thể tốn kém về mặt tính toán, đặc biệt nếu mô hình nhúng thay đổi hoặc dữ liệu được cập nhật thường xuyên. Một số Vector Database hỗ trợ cập nhật gia tăng, nhưng vẫn phức tạp hơn so với cập nhật trong SQL.
So sánh Vector Database với các giải pháp thay thế
Để hiểu rõ hơn về vị trí của Vector Database, cần so sánh nó với các giải pháp tìm kiếm và lưu trữ khác.
Vector Database vs. Elasticsearch
Elasticsearch là công cụ tìm kiếm văn bản mạnh mẽ dựa trên Apache Lucene, sử dụng chỉ mục đảo ngược (inverted index) để tìm kiếm từ khóa. Trong khi Elasticsearch xuất sắc trong tìm kiếm full-text và phân tích log, nó không được thiết kế để xử lý tìm kiếm ngữ nghĩa dựa trên vector. Tuy nhiên, Elasticsearch gần đây đã bổ sung hỗ trợ vector thông qua plugin, nhưng hiệu suất và độ chính xác vẫn không thể sánh bằng Vector Database chuyên dụng.
Vector Database vs. Cơ sở dữ liệu đồ thị (Graph Database)
Cơ sở dữ liệu đồ thị như Neo4j tập trung vào mối quan hệ giữa các thực thể, lưu trữ dữ liệu dưới dạng nút và cạnh. Trong khi đó, Vector Database tập trung vào sự tương tự về ngữ nghĩa hoặc đặc trưng. Hai loại cơ sở dữ liệu này bổ sung cho nhau: Graph Database quản lý mối quan hệ rõ ràng, còn Vector Database xử lý sự tương tự ngầm định.
Ứng dụng thực tế của Vector Database
Vector Database đang được ứng dụng rộng rãi trong nhiều lĩnh vực, từ công nghệ đến y tế và tài chính.
Hệ thống gợi ý (Recommendation Systems)
Các nền tảng như Netflix, Spotify và Amazon sử dụng Vector Database để gợi ý nội dung dựa trên sở thích người dùng. Mỗi người dùng và mỗi sản phẩm được biểu diễn bằng vector. Khi người dùng xem một bộ phim, hệ thống tìm kiếm các vector phim gần nhất với vector người dùng để đưa ra gợi ý. Phương pháp này cho phép gợi ý chính xác hơn nhiều so với các phương pháp lọc cộng tác truyền thống.
Tìm kiếm hình ảnh và nhận dạng đối tượng
Google Images và Pinterest sử dụng Vector Database để cho phép người dùng tìm kiếm hình ảnh bằng hình ảnh. Khi bạn tải lên một bức ảnh, hệ thống sẽ tạo vector cho bức ảnh đó và tìm kiếm các vector hình ảnh tương tự trong cơ sở dữ liệu. Ứng dụng này cũng được sử dụng trong an ninh để nhận dạng khuôn mặt và trong y tế để phân tích hình ảnh y khoa.
Chatbot và trợ lý ảo thông minh
Các chatbot hiện đại như ChatGPT và các trợ lý ảo doanh nghiệp sử dụng Vector Database để lưu trữ kiến thức và ngữ cảnh hội thoại. Khi người dùng đặt câu hỏi, hệ thống tìm kiếm các đoạn văn bản có ngữ nghĩa tương tự trong cơ sở dữ liệu để tạo ra câu trả lời chính xác và phù hợp với ngữ cảnh. Điều này giúp chatbot không chỉ trả lời đúng mà còn hiểu được ý định thực sự của người dùng.
Phát hiện gian lận trong tài chính
Các ngân hàng và tổ chức tài chính sử dụng Vector Database để phát hiện các giao dịch bất thường. Mỗi giao dịch được biểu diễn bằng vector dựa trên các đặc trưng như số tiền, thời gian, vị trí địa lý và lịch sử giao dịch. Các giao dịch gian lận thường có vector khác biệt so với các giao dịch hợp pháp, cho phép hệ thống phát hiện và cảnh báo kịp thời.
Xử lý ngôn ngữ tự nhiên (NLP)
Vector Database là nền tảng cho nhiều ứng dụng NLP như dịch máy, phân tích cảm xúc và tóm tắt văn bản. Bằng cách lưu trữ các vector ngữ nghĩa của câu và đoạn văn, hệ thống có thể hiểu được ngữ cảnh và mối quan hệ giữa các phần văn bản, từ đó tạo ra kết quả chính xác hơn.
Sai lầm thường gặp khi sử dụng Vector Database và cách tránh
Nhiều doanh nghiệp và nhà phát triển mắc phải những sai lầm phổ biến khi triển khai Vector Database, dẫn đến hiệu suất kém hoặc chi phí cao.
Chọn sai mô hình nhúng
Sai lầm phổ biến nhất là sử dụng một mô hình nhúng duy nhất cho mọi loại dữ liệu. Mỗi lĩnh vực và kiểu dữ liệu đòi hỏi mô hình nhúng khác nhau. Ví dụ, mô hình BERT phù hợp cho văn bản tiếng Anh nhưng có thể không hiệu quả cho tiếng Việt. Cách tránh là thử nghiệm nhiều mô hình khác nhau và đánh giá độ chính xác trên tập dữ liệu thực tế trước khi triển khai.
Nhiều người sử dụng cài đặt mặc định của Vector Database mà không điều chỉnh các tham số chỉ mục. Điều này có thể dẫn đến tốc độ truy vấn chậm hoặc độ chính xác thấp. Các tham số như số lượng cluster trong IVF, số lớp trong HNSW, và ngưỡng độ chính xác cần được tinh chỉnh dựa trên đặc thù dữ liệu và yêu cầu hiệu suất.
Bỏ qua việc quản lý metadata
Vector Database không chỉ lưu trữ vector mà còn cần quản lý metadata đi kèm. Nhiều người chỉ tập trung vào vector mà quên mất việc tối ưu hóa lưu trữ và truy vấn metadata. Điều này dẫn đến hiệu suất kém khi cần lọc dữ liệu theo các tiêu chí bổ sung như thời gian, danh mục hoặc vị trí địa lý.
Không có chiến lược cập nhật dữ liệu
Khi dữ liệu thay đổi thường xuyên, việc không có chiến lược cập nhật vector phù hợp có thể dẫn đến kết quả truy vấn lỗi thời. Cần xây dựng quy trình cập nhật gia tăng hoặc định kỳ, đồng thời cân nhắc giữa tần suất cập nhật và chi phí tính toán.
Lưu ý quan trọng khi triển khai Vector Database
Để triển khai Vector Database thành công, cần lưu ý một số điểm quan trọng sau đây.
Lựa chọn giải pháp phù hợp với quy mô
Thị trường hiện có nhiều giải pháp Vector Database khác nhau, từ mã nguồn mở như Milvus, Qdrant, Weaviate đến các dịch vụ đám mây như Pinecone, Amazon Kendra. Doanh nghiệp nhỏ có thể bắt đầu với các giải pháp mã nguồn mở, trong khi doanh nghiệp lớn với yêu cầu cao về hiệu suất và bảo mật nên cân nhắc các dịch vụ đám mây chuyên nghiệp.
Đảm bảo bảo mật và quyền riêng tư
Vector Database thường lưu trữ dữ liệu nhạy cảm như thông tin khách hàng, hình ảnh y tế hoặc dữ liệu tài chính. Cần đảm bảo mã hóa dữ liệu ở cả trạng thái lưu trữ và truyền tải, đồng thời thiết lập các chính sách kiểm soát truy cập chặt chẽ. Một số Vector Database hỗ trợ mã hóa đồng hình (homomorphic encryption) cho phép truy vấn trên dữ liệu đã mã hóa.
Kết hợp với cơ sở dữ liệu truyền thống
Vector Database không thay thế hoàn toàn cơ sở dữ liệu truyền thống mà nên được sử dụng như một thành phần bổ sung. Kiến trúc phổ biến là sử dụng SQL cho các giao dịch và báo cáo, đồng thời sử dụng Vector Database cho tìm kiếm ngữ nghĩa và gợi ý. Việc đồng bộ dữ liệu giữa hai hệ thống cần được thiết kế cẩn thận để đảm bảo tính nhất quán.
Câu hỏi thường gặp về Vector Database
Vector Database có thể thay thế hoàn toàn cơ sở dữ liệu SQL không?
Không. Vector Database được thiết kế cho các tác vụ tìm kiếm tương tự và xử lý dữ liệu phi cấu trúc, trong khi SQL vượt trội trong quản lý giao dịch, truy vấn chính xác và báo cáo. Hai loại cơ sở dữ liệu này bổ sung cho nhau và thường được sử dụng song song trong các hệ thống hiện đại.
Chi phí triển khai Vector Database có cao không?
Chi phí phụ thuộc vào quy mô dữ liệu và yêu cầu hiệu suất. Các giải pháp mã nguồn mở có thể triển khai miễn phí trên máy chủ riêng, nhưng đòi hỏi chi phí nhân sự vận hành. Các dịch vụ đám mây tính phí dựa trên dung lượng lưu trữ và số lượng truy vấn, thường dao động từ vài trăm đến vài nghìn đô la mỗi tháng cho doanh nghiệp vừa và nhỏ.
Làm thế nào để đánh giá hiệu suất của Vector Database?
Hiệu suất được đánh giá dựa trên ba chỉ số chính: độ trễ truy vấn (latency), thông lượng (throughput) và độ chính xác (recall). Các bài kiểm tra thường sử dụng bộ dữ liệu chuẩn như SIFT1M hoặc Deep1B để so sánh giữa các giải pháp. Ngoài ra, cần đo lường thời gian xây dựng chỉ mục và dung lượng bộ nhớ sử dụng.
Vector Database có hỗ trợ dữ liệu thời gian thực không?
Hầu hết các Vector Database hiện đại đều hỗ trợ cập nhật và truy vấn thời gian thực. Tuy nhiên, tốc độ cập nhật có thể chậm hơn so với cơ sở dữ liệu truyền thống do cần tính toán lại chỉ mục vector. Một số giải pháp hỗ trợ cập nhật gia tăng để giảm thiểu độ trễ.
Có cần kiến thức về machine learning để sử dụng Vector Database không?
Kiến thức cơ bản về machine learning và vector nhúng là cần thiết để triển khai và tối ưu hóa Vector Database hiệu quả. Tuy nhiên, nhiều dịch vụ đám mây cung cấp API đơn giản hóa, cho phép các nhà phát triển không chuyên về ML vẫn có thể sử dụng được.
Kết luận
Vector Database đang trở thành một công nghệ nền tảng không thể thiếu trong kỷ nguyên AI và dữ liệu lớn. Khả năng lưu trữ và truy vấn dữ liệu phi cấu trúc dựa trên ngữ nghĩa đã mở ra những khả năng mới cho các ứng dụng thông minh, từ hệ thống gợi ý, tìm kiếm hình ảnh đến chatbot và phát hiện gian lận.
Việc hiểu rõ Vector Database là gì, cách thức hoạt động và những lưu ý khi triển khai sẽ giúp doanh nghiệp và nhà phát triển tận dụng tối đa sức mạnh của công nghệ này. Trong bối cảnh dữ liệu phi cấu trúc ngày càng chiếm tỷ trọng lớn, đầu tư vào Vector Database không chỉ là xu hướng mà còn là chiến lược cạnh tranh dài hạn.
Để bắt đầu, hãy xác định rõ nhu cầu của bạn, lựa chọn giải pháp phù hợp và xây dựng kiến trúc hệ thống kết hợp hài hòa giữa Vector Database và cơ sở dữ liệu truyền thống. Với sự phát triển không ngừng của công nghệ, Vector Database chắc chắn sẽ còn tiến xa hơn nữa, mở ra những cánh cửa mới cho trí tuệ nhân tạo và xử lý dữ liệu thông minh.