Trong lĩnh vực trí tuệ nhân tạo và học máy, Model Training là quá trình cốt lõi quyết định sự thành công của mọi ứng dụng AI. Đây là giai đoạn mà mô hình học cách nhận diện các mẫu, đưa ra dự đoán và tối ưu hóa hiệu suất dựa trên dữ liệu đầu vào. Hiểu rõ về Model Training không chỉ giúp bạn xây dựng các hệ thống thông minh hiệu quả mà còn tránh được những sai lầm tốn kém trong quá trình phát triển.
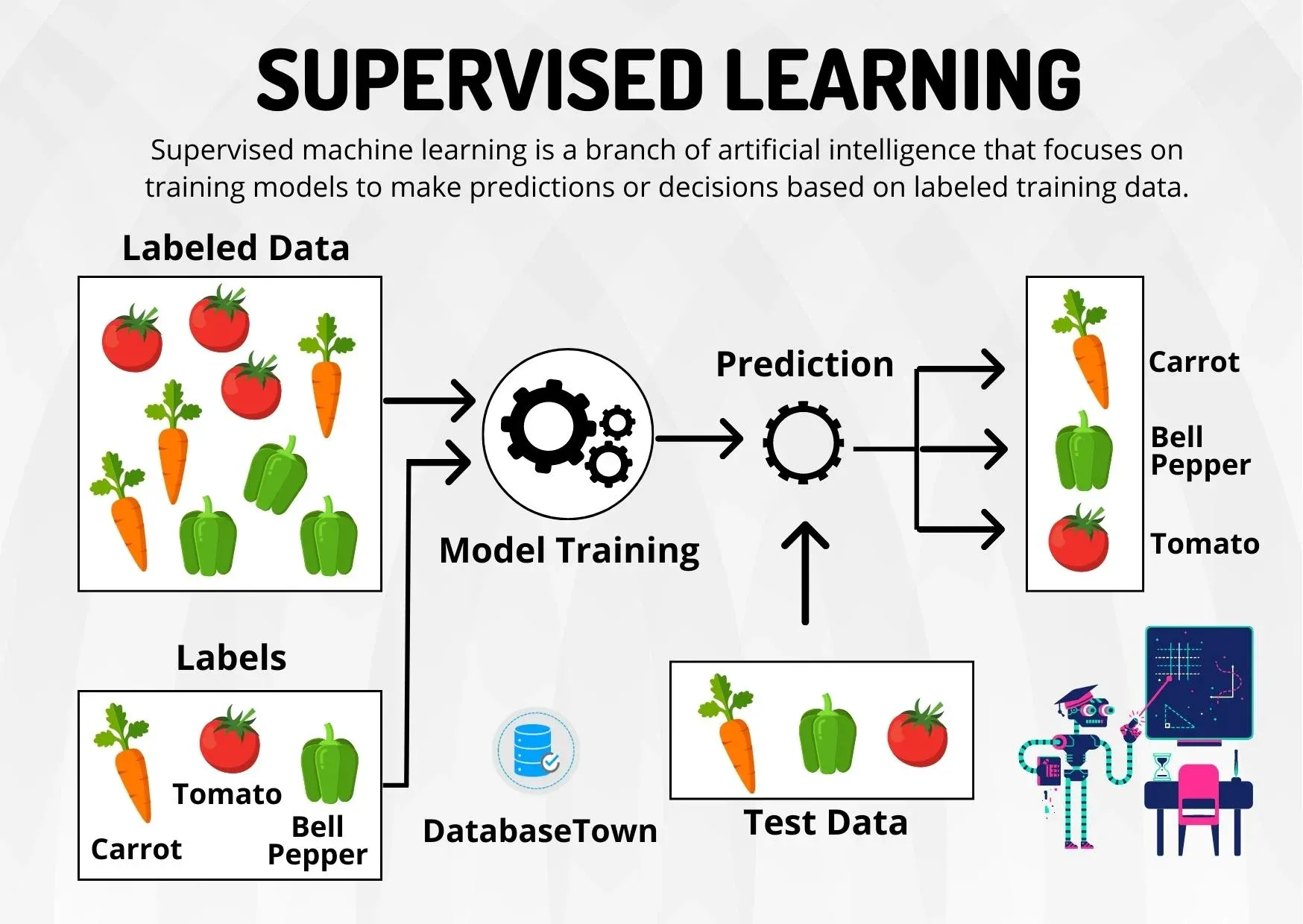
Model Training, hay còn gọi là huấn luyện mô hình, là quá trình cho phép một thuật toán học máy học từ dữ liệu để cải thiện độ chính xác trong việc thực hiện một nhiệm vụ cụ thể. Trong giai đoạn này, mô hình được cung cấp một tập dữ liệu huấn luyện bao gồm các đầu vào và đầu ra mong muốn, sau đó tự động điều chỉnh các tham số nội bộ để giảm thiểu sai số giữa dự đoán và giá trị thực tế.
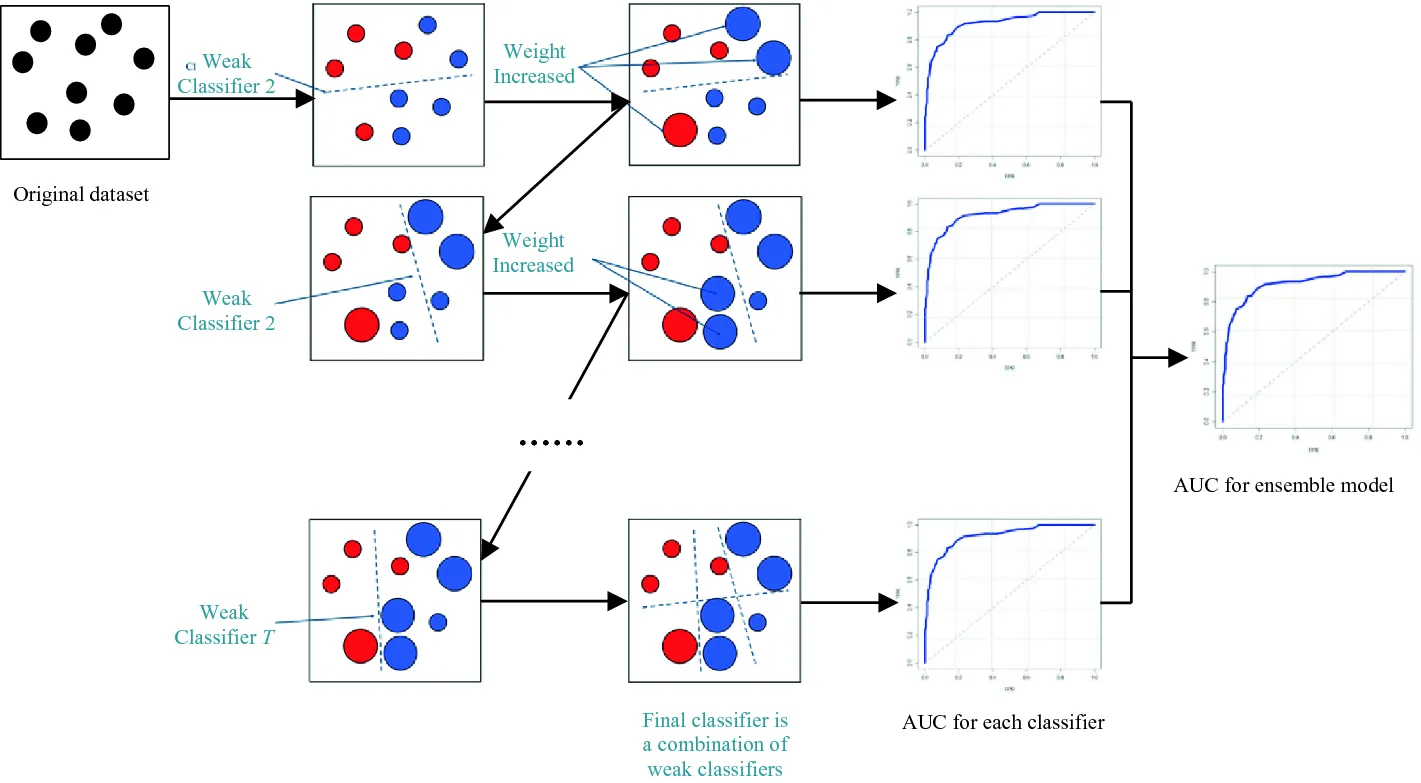
Bản chất của Model Training là quá trình tối ưu hóa hàm mất mát (loss function). Mỗi lần mô hình đưa ra dự đoán sai, nó sẽ tính toán mức độ sai lệch và cập nhật trọng số thông qua các kỹ thuật như gradient descent. Quá trình này lặp đi lặp lại hàng nghìn hoặc hàng triệu lần cho đến khi mô hình đạt được độ chính xác chấp nhận được.
Các thành phần chính trong Model Training
Dữ liệu huấn luyện
Dữ liệu là yếu tố quan trọng nhất trong Model Training. Chất lượng và số lượng dữ liệu ảnh hưởng trực tiếp đến khả năng học của mô hình. Dữ liệu huấn luyện cần được thu thập, làm sạch và gán nhãn cẩn thận trước khi đưa vào quá trình huấn luyện.
Dữ liệu có cấu trúc: bảng tính, cơ sở dữ liệu quan hệ
Dữ liệu phi cấu trúc: văn bản, hình ảnh, âm thanh, video
Dữ liệu bán cấu trúc: JSON, XML, log files
Thuật toán học
Mỗi thuật toán có cách tiếp cận khác nhau trong việc học từ dữ liệu. Lựa chọn thuật toán phù hợp phụ thuộc vào loại bài toán, kích thước dữ liệu và tài nguyên tính toán sẵn có.
Loại thuật toán
Ví dụ
Ứng dụng điển hình
Học có giám sát
Linear Regression, Random Forest
Phân loại, dự đoán giá trị
Học không giám sát
K-means, PCA
Phân cụm, giảm chiều dữ liệu
Học bán giám sát
Self-training, Co-training
Dữ liệu có ít nhãn
Học tăng cường
Q-learning, Deep Q-Network
Robot, game AI
Hàm mất mát và tối ưu hóa
Hàm mất mát đo lường mức độ sai lệch giữa dự đoán của mô hình và giá trị thực tế. Các hàm mất mát phổ biến bao gồm Mean Squared Error cho bài toán hồi quy và Cross-Entropy cho bài toán phân loại. Quá trình tối ưu hóa sử dụng các thuật toán như Stochastic Gradient Descent, Adam, hoặc RMSprop để tìm ra bộ trọng số tối ưu.
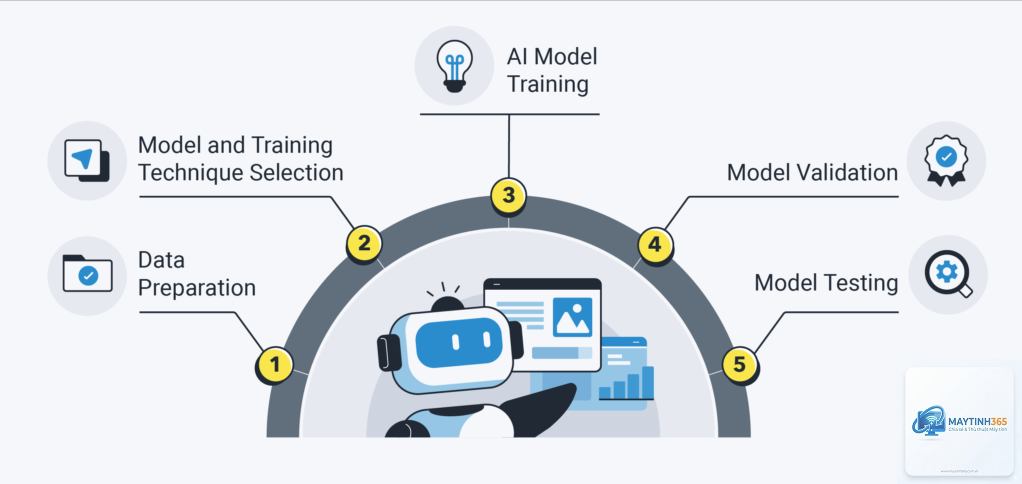
Quy trình Model Training chuẩn
Bước 1: Chuẩn bị dữ liệu
Trước khi bắt đầu Model Training, dữ liệu cần được xử lý và chuẩn hóa. Các bước bao gồm loại bỏ dữ liệu nhiễu, xử lý giá trị thiếu, chuẩn hóa đặc trưng và chia dữ liệu thành ba tập: huấn luyện, validation và kiểm tra.
Bước 2: Khởi tạo mô hình
Mô hình được khởi tạo với các tham số ngẫu nhiên hoặc từ các giá trị mặc định. Đối với các mô hình phức tạp như mạng nơ-ron sâu, việc khởi tạo trọng số đúng cách có thể ảnh hưởng đáng kể đến tốc độ hội tụ.
Bước 3: Vòng lặp huấn luyện
Quá trình huấn luyện diễn ra qua nhiều epoch. Mỗi epoch bao gồm việc đưa toàn bộ dữ liệu huấn luyện qua mô hình, tính toán loss, và cập nhật trọng số. Số lượng epoch cần được xác định dựa trên monitoring quá trình học để tránh overfitting.
Bước 4: Đánh giá và tinh chỉnh
Sau mỗi epoch, mô hình được đánh giá trên tập validation để kiểm tra hiệu suất. Các siêu tham số như learning rate, batch size, số lượng layer có thể được điều chỉnh dựa trên kết quả đánh giá này.
Các phương pháp Model Training phổ biến
Training từ đầu
Đây là phương pháp truyền thống, nơi mô hình được huấn luyện hoàn toàn từ dữ liệu mới mà không sử dụng kiến thức từ các mô hình đã có sẵn. Phương pháp này phù hợp khi có đủ dữ liệu và tài nguyên tính toán.
Transfer Learning
Transfer Learning cho phép tận dụng kiến thức từ một mô hình đã được huấn luyện trên một tác vụ tương tự. Phương pháp này giúp giảm thời gian huấn luyện và yêu cầu ít dữ liệu hơn, đặc biệt hiệu quả trong xử lý ảnh và ngôn ngữ tự nhiên.
Fine-tuning
Fine-tuning là quá trình điều chỉnh một mô hình đã được huấn luyện sẵn trên một tập dữ liệu mới. Kỹ thuật này thường được sử dụng để thích ứng các mô hình lớn như BERT, GPT vào các tác vụ cụ thể.
Lợi ích và hạn chế của Model Training
Lợi ích
Tự động hóa quy trình ra quyết định dựa trên dữ liệu
Khả năng xử lý khối lượng dữ liệu lớn vượt xa khả năng con người
Phát hiện các mẫu phức tạp mà con người khó nhận biết
Cải thiện độ chính xác theo thời gian khi có thêm dữ liệu
So sánh Model Training với các khái niệm liên quan
Khái niệm
Định nghĩa
Mối quan hệ với Model Training
Model Inference
Quá trình mô hình đưa ra dự đoán trên dữ liệu mới
Diễn ra sau khi Model Training hoàn tất
Model Evaluation
Đánh giá hiệu suất mô hình trên dữ liệu kiểm tra
Là một phần không thể thiếu trong quy trình
Hyperparameter Tuning
Tối ưu các tham số cấu hình mô hình
Diễn ra song song với Model Training
Ứng dụng thực tế của Model Training
Xử lý ngôn ngữ tự nhiên
Các mô hình ngôn ngữ lớn như GPT-4, BERT được huấn luyện trên hàng tỷ từ để hiểu và sinh văn bản. Quá trình Model Training cho các mô hình này có thể kéo dài hàng tuần trên hàng nghìn GPU, tiêu tốn hàng triệu đô la chi phí điện toán.
Thị giác máy tính
Trong lĩnh vực nhận dạng hình ảnh, Model Training giúp các mô hình học cách nhận diện vật thể, khuôn mặt, hoặc phân tích hình ảnh y tế. Ví dụ, mô hình ResNet-50 được huấn luyện trên tập dữ liệu ImageNet với hơn 14 triệu hình ảnh.
Hệ thống gợi ý
Các nền tảng như Netflix, Spotify sử dụng Model Training để phân tích hành vi người dùng và đưa ra gợi ý cá nhân hóa. Quá trình này xử lý hàng tỷ tương tác người dùng mỗi ngày.
Sai lầm thường gặp trong Model Training và cách tránh
Overfitting
Overfitting xảy ra khi mô hình học quá kỹ dữ liệu huấn luyện nhưng không khái quát hóa được trên dữ liệu mới. Dấu hiệu nhận biết là độ chính xác trên tập huấn luyện rất cao nhưng thấp trên tập kiểm tra. Cách khắc phục bao gồm sử dụng regularization, dropout, hoặc tăng kích thước dữ liệu.
Underfitting là tình trạng mô hình không học được các mẫu trong dữ liệu, thường do mô hình quá đơn giản hoặc thời gian huấn luyện không đủ. Giải pháp là tăng độ phức tạp của mô hình hoặc kéo dài thời gian huấn luyện.
Dữ liệu mất cân bằng
Khi một lớp dữ liệu chiếm ưu thế quá lớn, mô hình có xu hướng thiên vị lớp đó. Kỹ thuật xử lý bao gồm oversampling lớp thiểu số, undersampling lớp đa số, hoặc sử dụng weighted loss function.
Lưu ý quan trọng khi thực hiện Model Training
Việc lựa chọn metric đánh giá phù hợp là yếu tố then chốt. Accuracy không phải lúc nào cũng là thước đo tốt nhất, đặc biệt với dữ liệu mất cân bằng. Precision, Recall, F1-score thường cung cấp cái nhìn toàn diện hơn về hiệu suất mô hình.
Quản lý phiên bản dữ liệu và mô hình là cần thiết để đảm bảo khả năng tái lập kết quả. Sử dụng các công cụ như DVC, MLflow giúp theo dõi toàn bộ quá trình huấn luyện và so sánh hiệu suất giữa các phiên bản.
Tài nguyên tính toán cần được cân nhắc kỹ lưỡng. Đối với các mô hình lớn, việc sử dụng distributed training trên nhiều GPU hoặc TPU có thể giảm thời gian huấn luyện từ vài tháng xuống còn vài ngày.
Câu hỏi thường gặp về Model Training
Model Training mất bao lâu?
Thời gian huấn luyện phụ thuộc vào nhiều yếu tố: kích thước dữ liệu, độ phức tạp của mô hình, tài phần cứng. Một mô hình đơn giản có thể hoàn thành trong vài phút, trong khi các mô hình ngôn ngữ lớn có thể mất vài tuần.
Không có con số cố định, nhưng nguyên tắc chung là càng nhiều dữ liệu càng tốt. Đối với các bài toán đơn giản, vài nghìn mẫu có thể đủ. Với các tác vụ phức tạp như nhận dạng giọng nói, cần hàng triệu mẫu.
Làm thế nào để biết Model Training đã hoàn tất?
Quá trình huấn luyện được coi là hoàn tất khi loss trên tập validation không còn giảm đáng kể sau nhiều epoch liên tiếp. Kỹ thuật early stopping thường được sử dụng để tự động dừng huấn luyện khi phát hiện dấu hiệu overfitting.
Model Training có thể thất bại không?
Có, Model Training có thể thất bại vì nhiều lý do: dữ liệu nhiễu, lỗi trong quá trình tiền xử lý, lựa chọn siêu tham số không phù hợp, hoặc vấn đề về gradient vanishing/exploding trong mạng nơ-ron sâu.
Kết luận
Model Training là nền tảng của mọi ứng dụng trí tuệ nhân tạo hiện đại. Hiểu rõ quy trình, các thành phần và những cạm bẫy tiềm ẩn giúp bạn xây dựng các mô hình hiệu quả và đáng tin cậy. Từ việc chuẩn bị dữ liệu, lựa chọn thuật toán, đến tối ưu hóa siêu tham số, mỗi bước đều đóng vai trò quan trọng trong thành công cuối cùng.
Với sự phát triển không ngừng của công nghệ, các phương pháp Model Training ngày càng trở nên tinh vi và hiệu quả hơn. Việc cập nhật kiến thức liên tục và thực hành thường xuyên là chìa khóa để làm chủ quá trình này, từ đó tạo ra những giải pháp AI có giá trị thực tiễn cao.