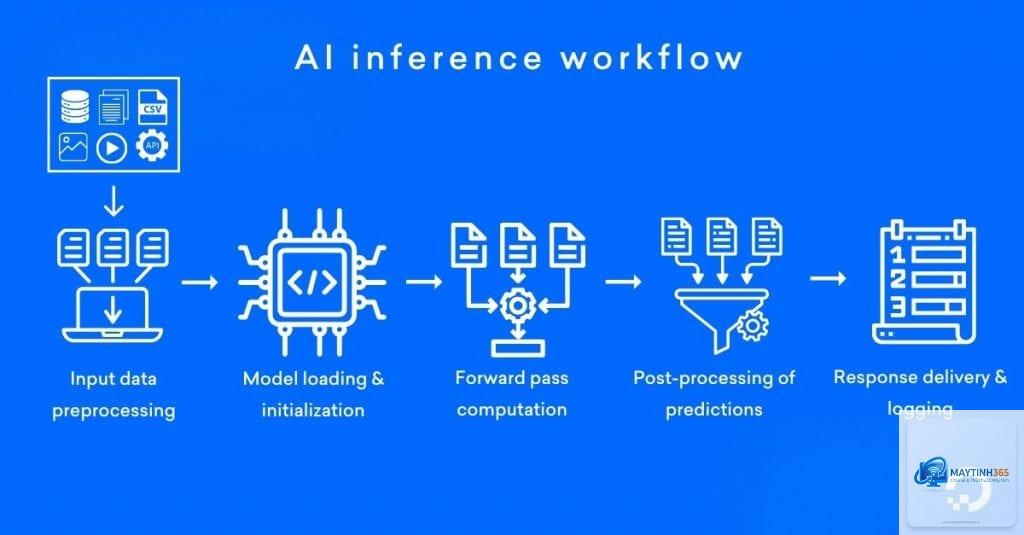
Trong bối cảnh trí tuệ nhân tạo phát triển như vũ bão, thuật ngữ Inference AI ngày càng xuất hiện nhiều trong các cuộc thảo luận về công nghệ. Vậy Inference AI là gì và tại sao nó lại quan trọng đến vậy? Khác với quá trình huấn luyện tốn kém và kéo dài, inference (suy luận) là giai đoạn mô hình AI đã được đào tạo bắt đầu đưa ra dự đoán, phân loại hoặc tạo ra nội dung dựa trên dữ liệu đầu vào mới. Đây chính là lúc AI thể hiện giá trị thực tế, từ việc nhận diện khuôn mặt trên điện thoại cho đến tạo văn bản với ChatGPT. Bài viết này sẽ đi sâu vào bản chất, cơ chế hoạt động và những ứng dụng không thể bỏ qua của inference AI.
Inference AI, hay còn gọi là suy luận AI, là quá trình một mô hình học máy (machine learning) đã được huấn luyện sử dụng kiến thức đã học để xử lý dữ liệu mới và đưa ra kết quả đầu ra. Nếu quá trình training giống như việc một học sinh học thuộc bài và làm bài tập, thì inference chính là lúc học sinh đó bước vào phòng thi và áp dụng kiến thức để giải quyết đề thi mới.
Về mặt kỹ thuật, inference liên quan đến việc chạy dữ liệu đầu vào qua mạng nơ-ron (neural network) đã được tối ưu hóa. Mô hình sẽ thực hiện các phép tính toán học phức tạp, nhân ma trận và áp dụng các hàm kích hoạt để đưa ra quyết định cuối cùng. Quá trình này diễn ra trong mili giây hoặc giây, tùy thuộc vào độ phức tạp của mô hình và phần cứng sử dụng.
Phân biệt Training và Inference trong AI
Để hiểu rõ inference AI là gì, cần phân biệt rõ ràng giữa hai giai đoạn cốt lõi: huấn luyện (training) và suy luận (inference).
Tiêu chí
Training (Huấn luyện)
Inference (Suy luận)
Mục đích
Học từ dữ liệu, tối ưu trọng số mô hình
Áp dụng mô hình đã học vào dữ liệu mới
Khối lượng tính toán
Cực kỳ lớn, cần GPU/TPU mạnh, hàng giờ đến hàng tuần
Nhẹ hơn nhiều, có thể chạy trên CPU hoặc thiết bị biên
Dữ liệu đầu vào
Hàng triệu mẫu dữ liệu có nhãn
Dữ liệu thực tế, chưa từng thấy trước đó
Độ trễ (Latency)
Không quan trọng
Cực kỳ quan trọng, yêu cầu phản hồi nhanh
Năng lượng tiêu thụ
Rất cao
Thấp hơn, tối ưu cho triển khai thực tế
Ví dụ
Huấn luyện GPT-4 trên siêu máy tính
ChatGPT trả lời câu hỏi của người dùng
Cơ chế hoạt động của Inference AI
Quá trình inference AI diễn ra theo một luồng xử lý có cấu trúc chặt chẽ. Đầu tiên, dữ liệu đầu vào (ví dụ: một bức ảnh, một câu văn bản) được tiền xử lý để đưa về định dạng mà mô hình có thể hiểu được. Điều này bao gồm việc chuẩn hóa kích thước ảnh, mã hóa văn bản thành token, hoặc chuyển đổi âm thanh thành phổ tần số.
Sau đó, dữ liệu được đưa qua các lớp (layers) của mạng nơ-ron. Mỗi lớp thực hiện các phép biến đổi phi tuyến tính, trích xuất các đặc trưng ngày càng trừu tượng hơn. Lớp cuối cùng (output layer) sẽ tổng hợp thông tin và đưa ra dự đoán dưới dạng xác suất hoặc nhãn phân loại. Ví dụ, với mô hình nhận diện ảnh, đầu ra có thể là một vector xác suất cho các lớp như “mèo”, “chó”, “xe hơi”.
Vai trò của phần cứng trong Inference AI
Phần cứng đóng vai trò then chốt trong hiệu suất inference. Các GPU (Graphics Processing Unit) như NVIDIA A100 hay H100 được tối ưu hóa cho tính toán song song, giúp tăng tốc độ suy luận đáng kể. Bên cạnh đó, các chip chuyên dụng như TPU (Tensor Processing Unit) của Google hay NPU (Neural Processing Unit) trên điện thoại thông minh được thiết kế riêng để chạy inference với mức năng lượng thấp nhất.
Các loại Inference AI phổ biến
Inference AI có thể được phân loại dựa trên thời điểm và cách thức thực hiện. Hiểu được các loại hình này giúp doanh nghiệp lựa chọn giải pháp phù hợp.
Inference trực tuyến (Online Inference): Diễn ra theo thời gian thực, ngay khi nhận được yêu cầu từ người dùng. Ví dụ: Google Dịch, trợ lý ảo Siri, hệ thống gợi ý sản phẩm trên Shopee. Yêu cầu độ trễ cực thấp (dưới 100ms).
Inference ngoại tuyến (Offline/Batch Inference): Xử lý hàng loạt dữ liệu lớn trong một khoảng thời gian định trước. Ví dụ: phân tích dữ liệu khách hàng hàng đêm để tạo báo cáo, quét ảnh vệ tinh để phát hiện thay đổi địa hình. Không yêu cầu thời gian thực.
Inference trên thiết bị biên (Edge Inference): Chạy trực tiếp trên thiết bị như điện thoại, camera, cảm biến IoT mà không cần kết nối đám mây. Ví dụ: nhận diện khuôn mặt trên iPhone, phát hiện vật cản trên xe tự lái. Ưu điểm là bảo mật cao, độ trễ thấp.
Lợi ích vượt trội của Inference AI trong thực tế
Việc triển khai inference AI mang lại nhiều lợi ích thiết thực cho cả doanh nghiệp lẫn người dùng cuối. Không chỉ dừng lại ở việc tự động hóa, nó còn mở ra những khả năng mới mà trước đây con người không thể thực hiện được.
Tự động hóa quy trình: Inference AI cho phép tự động hóa các tác vụ lặp đi lặp lại như phân loại email, kiểm duyệt nội dung, chấm công bằng nhận diện khuôn mặt, giúp tiết kiệm hàng nghìn giờ lao động thủ công.
Cá nhân hóa trải nghiệm: Các nền tảng như Netflix, Spotify, TikTok sử dụng inference để phân tích hành vi người dùng và đề xuất nội dung phù hợp, tăng tỷ lệ tương tác lên đến 30-40%.
Ra quyết định nhanh chóng: Trong lĩnh vực tài chính, inference AI có thể phát hiện giao dịch gian lận trong vòng 0.1 giây, nhanh hơn gấp nhiều lần so với kiểm tra thủ công.
Tiết kiệm chi phí vận hành: Thay vì phải thuê đội ngũ nhân viên lớn, doanh nghiệp có thể triển khai một mô hình inference để xử lý khối lượng công việc tương đương với chi phí thấp hơn 50-70%.
Hạn chế và thách thức của Inference AI
Mặc dù mạnh mẽ, inference AI không phải là giải pháp hoàn hảo. Có những thách thức kỹ thuật và phi kỹ thuật cần được giải quyết để đảm bảo hiệu quả tối ưu.
Độ chính xác không tuyệt đối: Mô hình inference có thể đưa ra kết quả sai nếu dữ liệu đầu vào khác biệt quá lớn so với dữ liệu huấn luyện. Đây gọi là hiện tượng “distribution shift”.
Yêu cầu tài nguyên phần cứng: Các mô hình lớn như GPT-4 hay Stable Diffusion yêu cầu GPU mạnh để chạy inference, gây khó khăn cho các doanh nghiệp nhỏ hoặc thiết bị di động.
Vấn đề về độ trễ: Đối với các ứng dụng thời gian thực như xe tự lái, bất kỳ độ trễ nào cũng có thể gây ra hậu quả nghiêm trọng. Tối ưu hóa inference để đạt tốc độ mili giây là một thách thức lớn.
Bảo mật và quyền riêng tư: Khi dữ liệu nhạy cảm được gửi lên đám mây để inference, nguy cơ rò rỉ thông tin luôn hiện hữu. Edge inference là giải pháp nhưng lại hạn chế về sức mạnh tính toán.
Ứng dụng thực tế của Inference AI trong các ngành
Inference AI đã và đang thay đổi cách vận hành của nhiều ngành công nghiệp.
Y tế và chăm sóc sức khỏe
Trong lĩnh vực y tế, inference AI được sử dụng để phân tích hình ảnh X-quang, CT scan và MRI, hỗ trợ bác sĩ phát hiện sớm các khối u, tổn thương. Một nghiên cứu từ Stanford cho thấy mô hình AI có thể phát hiện ung thư phổi với độ chính xác lên đến 94%, cao hơn bác sĩ chuyên khoa trung bình 11%.
Tài chính ngân hàng
Các ngân hàng lớn như JPMorgan Chase sử dụng inference AI để phát hiện giao dịch bất thường theo thời gian thực. Hệ thống có thể xử lý hàng triệu giao dịch mỗi ngày, đánh dấu những giao dịch có dấu hiệu rửa tiền hoặc gian lận thẻ tín dụng, giảm thiểu tổn thất tài chính lên đến 40%.
Sản xuất và công nghiệp
Trong các nhà máy thông minh, inference AI chạy trên camera giám sát để phát hiện lỗi sản phẩm trên dây chuyền sản xuất. Ví dụ, nhà máy của Siemens sử dụng AI để kiểm tra chất linh kiện điện tử với tốc độ 100 sản phẩm/phút, giảm tỷ lệ lỗi từ 5% xuống còn 0.5%.
Thương mại điện tử
Amazon và Alibaba sử dụng inference AI cho hệ thống gợi ý sản phẩm, tìm kiếm bằng hình ảnh và chatbot hỗ trợ khách hàng. Hệ thống này phân tích lịch sử mua hàng, hành vi duyệt web để đưa ra đề xuất chính xác, tăng doanh thu trung bình 15-25%.
Sai lầm thường gặp khi triển khai Inference AI
Nhiều doanh nghiệp mắc phải những sai lầm phổ biến khi áp dụng inference AI, dẫn đến hiệu quả không như mong đợi. Nhận diện và tránh những lỗi này là chìa khóa để thành công.
Không tối ưu hóa mô hình trước khi triển khai: Nhiều đội ngũ kỹ thuật đưa trực tiếp mô hình huấn luyện vào sản xuất mà không qua bước tối ưu như lượng tử hóa (quantization) hoặc cắt tỉa (pruning). Điều này làm tăng độ trễ và tiêu tốn tài nguyên không cần thiết.
Bỏ qua kiểm thử trên dữ liệu thực tế: Mô hình có thể hoạt động hoàn hảo trên tập kiểm thử trong phòng lab nhưng lại thất bại khi gặp dữ liệu thực tế đa dạng. Cần có quy trình A/B testing và monitoring liên tục.
Chọn sai phần cứng: Sử dụng CPU cho inference các mô hình deep learning lớn sẽ dẫn đến hiệu suất kém. Cần cân nhắc giữa GPU, TPU, FPGA hoặc ASIC tùy theo nhu cầu về tốc độ và chi phí.
Không có kế hoạch mở rộng: Khi lượng người dùng tăng đột biến, hệ thống inference có thể bị quá tải. Cần thiết kế kiến trúc có khả năng scale ngang (horizontal scaling) ngay từ đầu.
Lưu ý quan trọng khi làm việc với Inference AI
Để khai thác tối đa tiềm năng của inference AI, có một số nguyên tắc vàng cần ghi nhớ. Những lưu ý này giúp đảm bảo hệ thống vận hành ổn định, an toàn và hiệu quả.
Đánh giá độ chính xác định kỳ: Mô hình inference có thể bị “suy thoái” theo thời gian do dữ liệu thay đổi. Thiết lập pipeline tự động đánh giá và retrain mô hình hàng tháng hoặc hàng quý.
Ưu tiên bảo mật dữ liệu: Sử dụng mã hóa đầu cuối (end-to-end encryption) khi truyền dữ liệu lên cloud inference. Đối với dữ liệu cực kỳ nhạy cảm, nên triển khai edge inference.
Tối ưu chi phí: Inference trên cloud có thể tốn kém nếu không được quản lý tốt. Sử dụng spot instances, auto-scaling và caching kết quả cho các truy vấn trùng lặp để giảm chi phí đến 60%.
Tuân thủ quy định pháp lý: Các ngành như y tế, tài chính có những quy định nghiêm ngặt về AI. Đảm bảo mô hình inference của bạn tuân thủ GDPR, HIPAA hoặc các tiêu chuẩn địa phương.
Inference AI khác gì so với Machine Learning thông thường?
Machine learning là lĩnh vực rộng bao gồm cả training và inference. Inference AI là một giai đoạn cụ thể trong vòng đời của một mô hình ML, nơi mô hình được sử dụng để đưa ra dự đoán. Nói cách khác, ML là khái niệm tổng quát, còn inference là hành động áp dụng ML vào thực tế.
Có thể chạy Inference AI trên điện thoại thông minh không?
Hoàn toàn có thể. Các chip NPU (Neural Processing Unit) trên điện thoại như Apple A17 Pro, Snapdragon 8 Gen 3 được thiết kế riêng cho inference. Các ứng dụng như Google Photos, nhận diện khuôn mặt, dịch thuật ngoại tuyến đều chạy inference ngay trên thiết bị.
Chi phí triển khai Inference AI có đắt không?
Chi phí phụ thuộc vào quy mô và yêu cầu kỹ thuật. Đối với doanh nghiệp nhỏ, có thể bắt đầu với các dịch vụ cloud inference như AWS SageMaker, Google Cloud AI Platform với chi phí vài trăm đô mỗi tháng. Đối với hệ thống lớn, chi phí có thể lên đến hàng chục nghìn đô mỗi tháng cho phần cứng và điện năng.
Làm thế nào để tối ưu tốc độ Inference AI?
Có nhiều kỹ thuật tối ưu: lượng tử hóa (quantization) giảm độ chính xác số học từ FP32 xuống INT8, cắt tỉa (pruning) loại bỏ các kết nối không quan trọng, và sử dụng các framework tối ưu như TensorRT, ONNX Runtime. Kết hợp các kỹ thuật này có thể tăng tốc độ inference lên 3-5 lần.
Inference AI không thay thế con người mà là công cụ hỗ trợ đắc lực. Nó xử lý các tác vụ lặp đi lặp lại, phân tích khối lượng dữ liệu lớn, nhưng vẫn cần con người đưa ra quyết định cuối cùng trong các tình huống phức tạp, nhạy cảm hoặc đòi hỏi đạo đức.
Kết luận
Inference AI là giai đoạn then chốt biến những mô hình trí tuệ nhân tạo từ phòng thí nghiệm thành công cụ hữu ích trong đời sống hàng ngày. Từ việc gợi ý sản phẩm, phát hiện bệnh tật đến điều khiển xe tự lái, inference AI đang âm thầm thay đổi thế giới xung quanh chúng ta. Hiểu rõ bản chất, cơ chế hoạt động và những thách thức của nó sẽ giúp doanh nghiệp và cá nhân tận dụng tối đa sức mạnh của công nghệ này. Trong tương lai, với sự phát triển của phần cứng chuyên dụng và các kỹ thuật tối ưu mới, inference AI sẽ còn trở nên nhanh hơn, rẻ hơn và phổ biến hơn nữa, mở ra những cánh cửa cơ hội chưa từng có cho nhân loại.