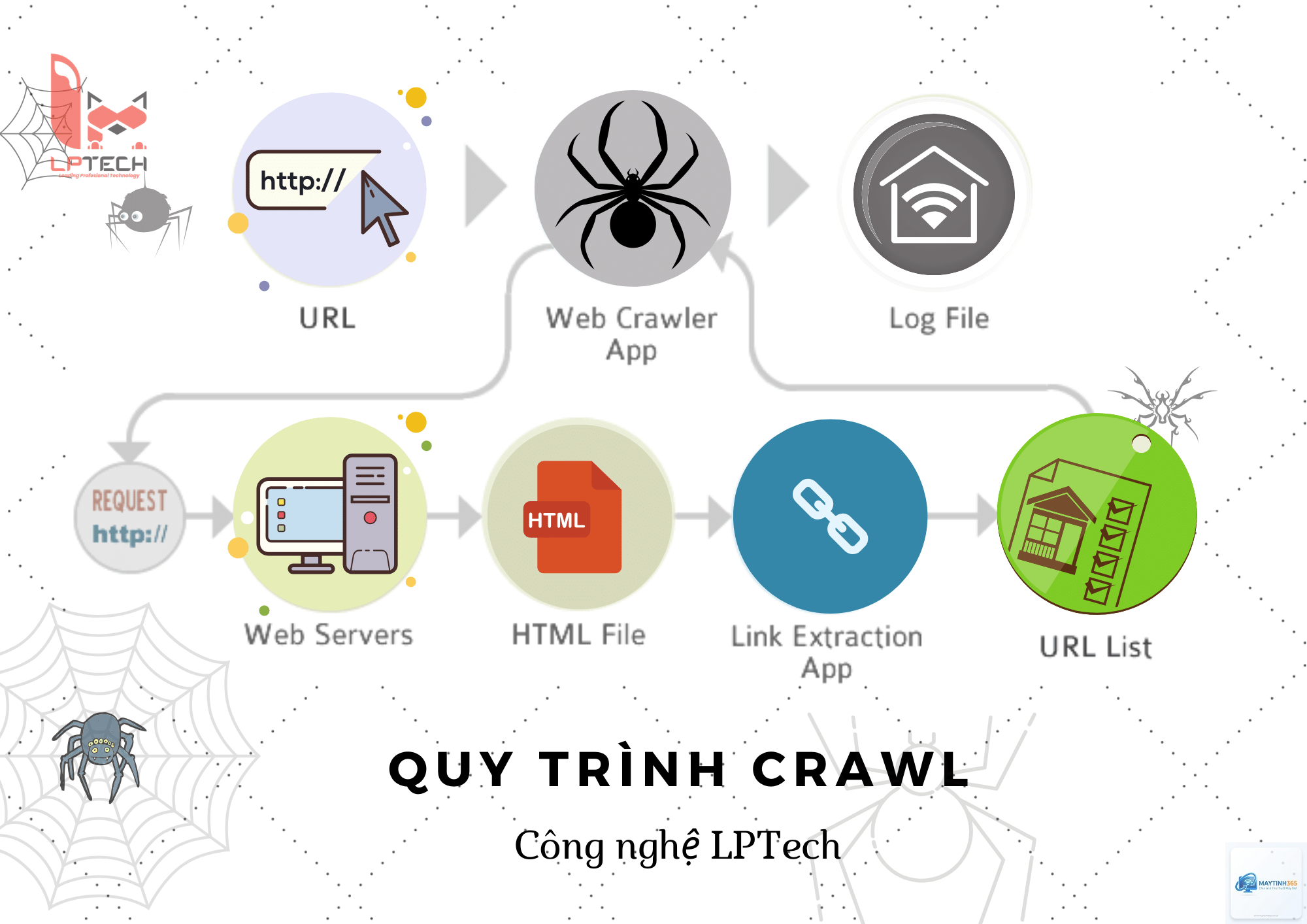
Trong thế giới internet rộng lớn, hàng tỷ trang web tồn tại và liên tục được cập nhật. Để người dùng có thể tìm kiếm thông tin một cách nhanh chóng, các công cụ tìm kiếm như Google, Bing hay Yahoo cần một hệ thống đặc biệt để khám phá và thu thập dữ liệu từ những trang web này. Hệ thống đó chính là crawler. Vậy crawler là gì và nó hoạt động ra sao? Bài viết này sẽ giải thích chi tiết từ khái niệm cơ bản đến các khía cạnh kỹ thuật chuyên sâu, giúp bạn hiểu rõ vai trò của crawler trong SEO và vận hành website.
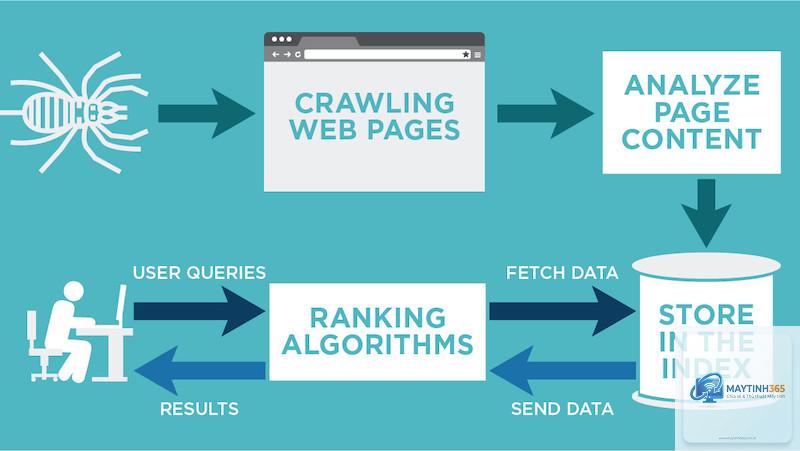
Crawler, còn được gọi là spider hay bot, là một chương trình tự động được thiết kế để duyệt qua các trang web trên internet một cách có hệ thống. Nhiệm vụ chính của crawler là tìm kiếm, tải xuống và lưu trữ nội dung từ các trang web để phục vụ cho mục đích lập chỉ mục của công cụ tìm kiếm. Khi một crawler truy cập vào website, nó sẽ đọc toàn bộ nội dung văn bản, mã HTML, liên kết và các tài nguyên khác, sau đó gửi dữ liệu này về máy chủ trung tâm để xử lý.
Thuật ngữ “crawler” bắt nguồn từ cách thức hoạt động của nó: giống như một con nhện (spider) bò trên mạng nhện, crawler di chuyển từ trang này sang trang khác thông qua các liên kết. Googlebot là crawler nổi tiếng nhất, thuộc sở hữu của Google, nhưng mỗi công cụ tìm kiếm lớn đều có crawler riêng như Bingbot của Microsoft hay Slurp của Yahoo.
Cơ chế hoạt động của Crawler
Quy trình thu thập dữ liệu cơ bản
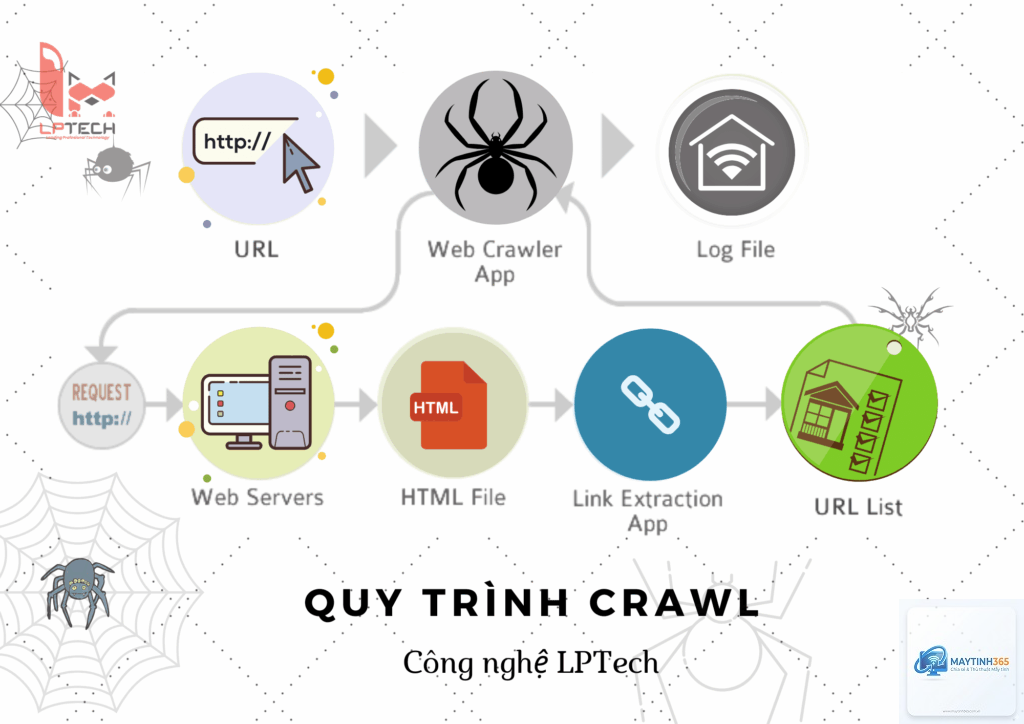
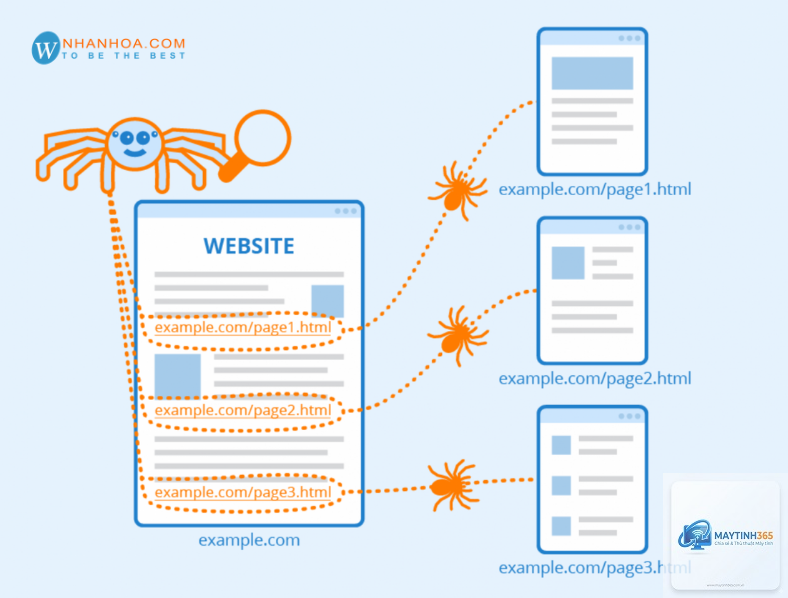
Crawler bắt đầu hành trình từ một danh sách các URL đã biết, thường được gọi là seed URLs. Danh sách này có thể bao gồm các trang web phổ biến, các URL từ sơ đồ trang web (sitemap) hoặc các liên kết được gửi qua công cụ dành cho quản trị web. Từ những URL ban đầu, crawler tải nội dung trang, phân tích mã HTML và trích xuất tất cả các liên kết (thẻ a href) có trong trang đó.
Sau khi thu thập xong một trang, crawler thêm các liên kết mới tìm được vào hàng đợi (queue) để tiếp tục duyệt. Quá trình này lặp đi lặp lại, tạo thành một mạng lưới liên kết khổng lồ. Crawler có khả năng xử lý hàng triệu trang mỗi ngày, nhưng nó phải tuân thủ các quy tắc nhất định để không làm quá tải máy chủ web.
Nguyên tắc lịch sự (Politeness Policy)
Một crawler chuyên nghiệp luôn tuân thủ chính sách lịch sự. Điều này có nghĩa là nó không gửi quá nhiều yêu cầu đến một máy chủ trong thời gian ngắn. Googlebot thường chờ vài giây giữa các lần truy cập vào cùng một website để tránh gây quá tải băng thông hoặc tài nguyên máy chủ. Nếu một website có tốc độ phản hồi chậm, crawler sẽ tự động giảm tần suất thu thập.
Vai trò của tệp robots.txt
Robots.txt là tệp văn bản đặt ở thư mục gốc của website, hướng dẫn crawler những khu vực nào được phép hoặc không được phép truy cập. Khi crawler đến một website, nó luôn kiểm tra tệp robots.txt trước tiên. Nếu tệp này chặn một thư mục cụ thể, crawler sẽ bỏ qua toàn bộ nội dung trong thư mục đó. Đây là công cụ quan trọng để quản trị viên web kiểm soát quá trình thu thập dữ liệu.
Phân loại các loại Crawler phổ biến
Loại Crawler
Mục đích chính
Ví dụ điển hình
Crawler công cụ tìm kiếm
Thu thập dữ liệu để lập chỉ mục tìm kiếm
Googlebot, Bingbot, Yandex Bot
Crawler kiểm tra SEO
Phân tích cấu trúc và lỗi kỹ thuật website
Screaming Frog, Sitebulb
Crawler giám sát nội dung
Phát hiện thay đổi nội dung hoặc vi phạm bản quyền
Copyscape, Diffbot
Crawler thương mại điện tử
So sánh giá và thu thập thông tin sản phẩm
PriceGrabber, Shopzilla
Tầm quan trọng của Crawler đối với SEO
Ảnh hưởng đến khả năng lập chỉ mục
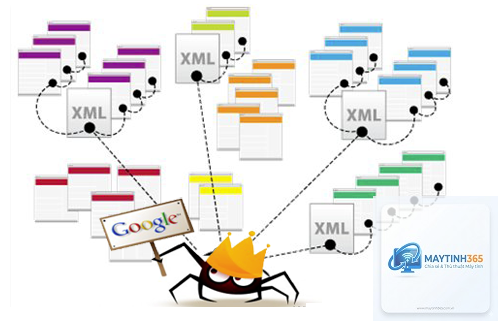
Nếu crawler không thể truy cập website của bạn, trang web đó sẽ không bao giờ xuất hiện trong kết quả tìm kiếm. Đây là lý do tại sao việc tối ưu hóa khả năng thu thập dữ liệu (crawlability) là bước đầu tiên trong bất kỳ chiến lược SEO kỹ thuật nào. Một website có cấu trúc liên kết rõ ràng, sitemap XML đầy đủ và thời gian tải trang nhanh sẽ được crawler đánh giá cao và thu thập thường xuyên hơn.
Ngân sách thu thập là số lượng trang mà crawler sẽ thu thập trên website của bạn trong một khoảng thời gian nhất định. Googlebot có nguồn lực hạn chế, vì vậy nó phải phân bổ thời gian và băng thông một cách hiệu quả. Các yếu tố ảnh hưởng đến crawl budget bao gồm kích thước website, tốc độ tải trang, tần suất cập nhật nội dung và mức độ uy tín của domain. Website càng lớn và càng quan trọng thì crawl budget càng cao.
Phát hiện nội dung mới
Crawler đóng vai trò then chốt trong việc phát hiện nội dung mới được đăng tải. Khi bạn xuất bản một bài viết mới, crawler cần phát hiện và thu thập nó càng sớm càng tốt để nội dung xuất hiện trong kết quả tìm kiếm. Việc gửi URL qua Google Search Console hoặc sử dụng sitemap động giúp đẩy nhanh quá trình này. Thời gian từ lúc đăng bài đến lúc được lập chỉ mục có thể dao động từ vài phút đến vài tuần, tùy thuộc vào tần suất crawler ghé thăm.
Các yếu tố ảnh hưởng đến hiệu suất của Crawler
Tốc độ tải trang
Tốc độ tải trang là yếu tố quan trọng nhất ảnh hưởng đến hiệu suất thu thập dữ liệu. Googlebot sử dụng phiên bản di động để thu thập dữ liệu từ năm 2020, vì vậy tốc độ trên thiết bị di động càng quan trọng. Một trang web tải chậm sẽ khiến crawler tốn nhiều thời gian hơn cho mỗi URL, dẫn đến việc thu thập được ít trang hơn trong cùng một khoảng thời gian. Các công cụ như PageSpeed Insights giúp đo lường và cải thiện tốc độ tải trang.
Cấu trúc liên kết nội bộ
Cấu trúc liên kết nội bộ logic giúp crawler dễ dàng khám phá tất cả các trang quan trọng trên website. Mỗi trang nên có ít nhất một liên kết từ một trang khác trong cùng website. Trang chủ thường nhận được nhiều lượt thu thập nhất, vì vậy các trang quan trọng nên được liên kết trực tiếp từ trang chủ hoặc từ các trang có thẩm quyền cao. Tránh tạo ra các trang mồ côi (orphan pages) không có liên kết đến từ bất kỳ đâu.
Độ sâu thu thập (Crawl Depth)
Độ sâu thu thập là số lần nhấp chuột cần thiết để đi từ trang chủ đến một trang cụ thể. Crawler thường ưu tiên các trang có độ sâu thấp hơn. Một trang nằm ở độ sâu 3 hoặc 4 vẫn có thể được thu thập, nhưng nếu độ sâu lên đến 7 hoặc 8, khả năng cao trang đó sẽ bị bỏ qua. Giữ độ sâu thu thập dưới 4 click cho các trang quan trọng là một thực hành tốt trong SEO.
Các công cụ như Screaming Frog SEO Spider cho phép bạn mô phỏng quá trình thu thập dữ liệu của Googlebot trên website của mình.
Crawler tiêu tốn băng thông và tài nguyên máy chủ, nhưng mức độ ảnh hưởng thường không đáng kể đối với website thông thường. Với website lớn có hàng triệu trang, tác động có thể rõ rệt hơn. Sử dụng CDN và tối ưu hóa máy chủ giúp giảm thiểu ảnh hưởng này.
Làm thế nào để biết crawler đang truy cập website?
Có, Googlebot hiện tại có thể render và thu thập nội dung JavaScript, nhưng quá trình này tốn nhiều tài nguyên hơn so với HTML tĩnh. Nội dung quan trọng nên được hiển thị ở dạng HTML để đảm bảo crawler có thể truy cập dễ dàng.
Tại sao crawler không thu thập trang của tôi?
Nguyên nhân phổ biến bao gồm robots.txt chặn truy cập, thẻ meta robots noindex, liên kết hỏng, thời gian tải trang quá lâu hoặc website bị phạt bởi Google. Kiểm tra từng yếu tố này trong Google Search Console để xác định vấn đề cụ thể.
Crawler và bot có giống nhau không?
Về bản chất, crawler là một loại bot chuyên dụng cho việc thu thập dữ liệu web. Tuy nhiên, bot có phạm vi rộng hơn, bao gồm chatbot, bot mạng xã hội, bot kiểm tra bảo mật và nhiều loại khác. Tất cả crawler đều là bot, nhưng không phải bot nào cũng là crawler.
Kết luận
Crawler là xương sống của hệ thống tìm kiếm internet, đóng vai trò không thể thiếu trong việc kết nối người dùng với thông tin họ cần. Hiểu rõ crawler là gì và cách nó hoạt động giúp bạn xây dựng website thân thiện với công cụ tìm kiếm, tối ưu hóa ngân sách thu thập và cải thiện thứ hạng tìm kiếm. Từ việc kiểm soát robots.txt, tối ưu hóa cấu trúc liên kết nội bộ đến phân tích log file máy chủ, mỗi khía cạnh đều góp phần vào thành công của chiến lược SEO tổng thể.
Việc theo dõi hành vi của crawler không phải là công việc một lần mà là quá trình liên tục. Cập nhật thuật toán của Google, thay đổi trong hành vi người dùng và sự phát triển của website đều ảnh hưởng đến cách crawler tương tác với nội dung của bạn. Dành thời gian định kỳ kiểm tra khả năng thu thập dữ liệu và điều chỉnh chiến lược sẽ đảm bảo website luôn trong tình trạng tối ưu nhất cho cả crawler và người dùng.