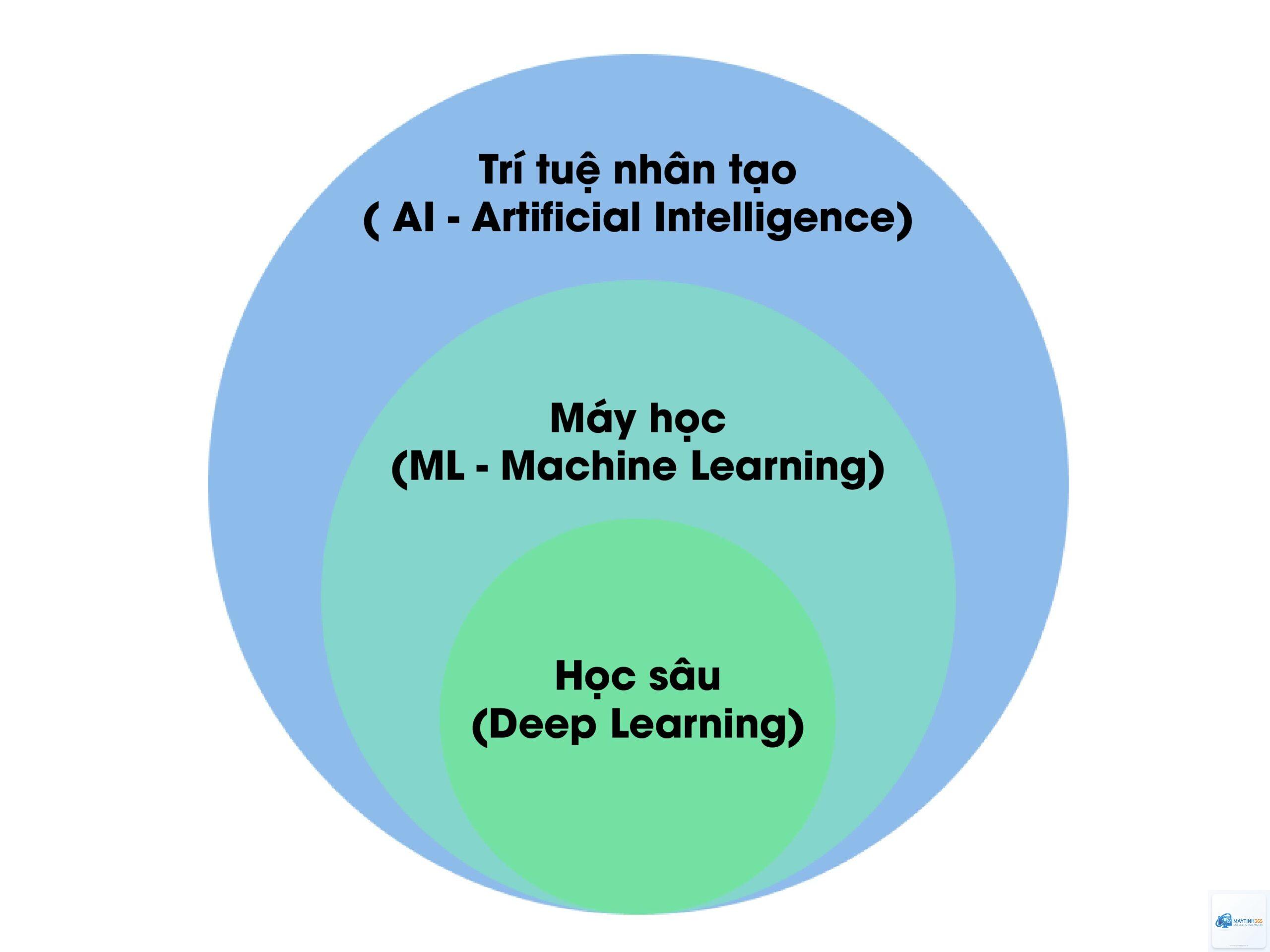
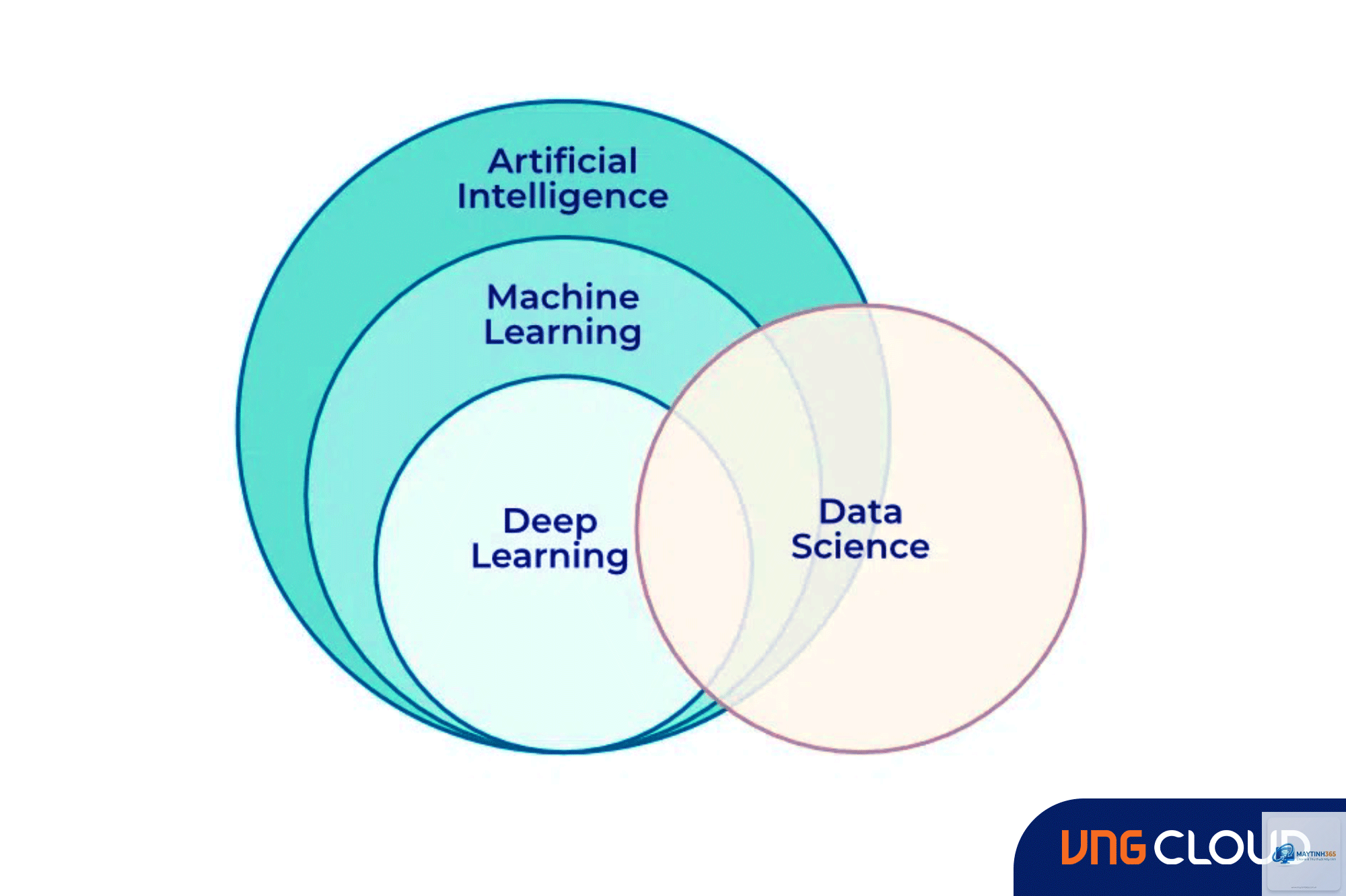
Deep Learning (học sâu) là một nhánh con của Machine Learning (học máy) dựa trên mạng nơ-ron nhân tạo với nhiều lớp ẩn. Công nghệ này mô phỏng cách thức hoạt động của bộ não con người để xử lý dữ liệu phức tạp, từ đó đưa ra quyết định hoặc dự đoán chính xác. Deep Learning đang là động lực chính đằng sau những đột phá như xe tự lái, trợ lý ảo, nhận diện khuôn mặt và dịch thuật tự động.
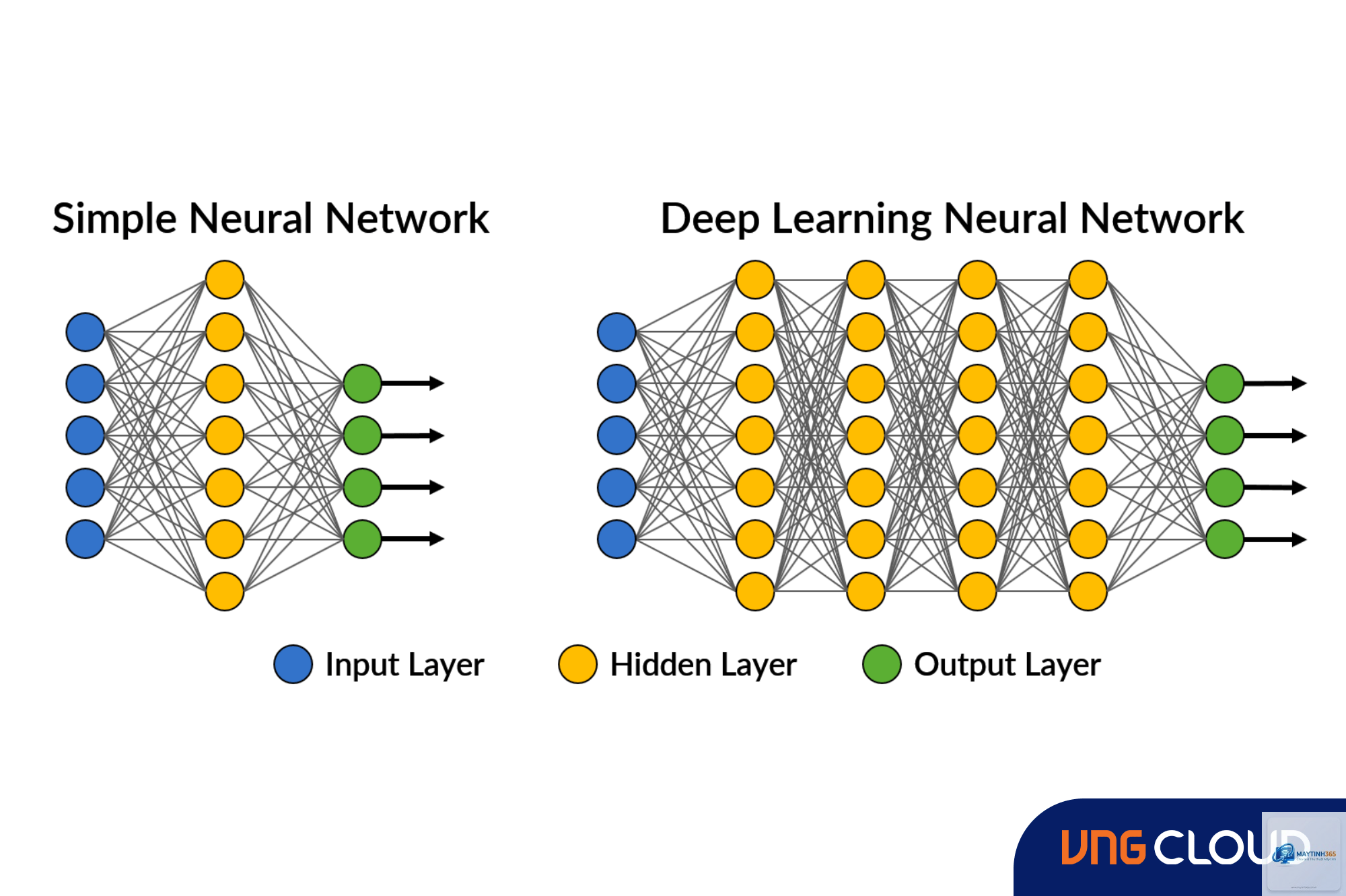
Deep Learning hoạt động dựa trên kiến trúc mạng nơ-ron sâu (Deep Neural Networks – DNN). Mỗi mạng bao gồm ba thành phần chính: lớp đầu vào (input layer), các lớp ẩn (hidden layers) và lớp đầu ra (output layer). Số lượng lớp ẩn càng nhiều, mạng càng “sâu” và khả năng học các đặc trưng trừu tượng càng cao.
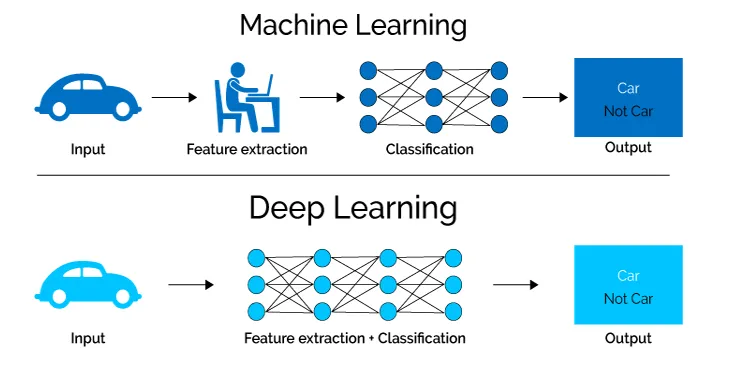
Khác với các thuật toán Machine Learning truyền thống yêu cầu con người phải trích xuất đặc trưng thủ công (feature engineering), Deep Learning tự động học các đặc trưng từ dữ liệu thô. Ví dụ, khi xử lý ảnh chụp mèo, lớp đầu tiên học các cạnh và đường nét, lớp giữa học hình dạng tai và mũi, lớp cuối cùng nhận diện tổng thể con mèo.
Các loại kiến trúc Deep Learning phổ biến
Mạng nơ-ron tích chập (CNN – Convolutional Neural Network)
CNN được thiết kế đặc biệt cho dữ liệu không gian như ảnh và video. Kiến trúc này sử dụng các lớp tích chập để quét qua ảnh, phát hiện các đặc trưng cục bộ như cạnh, góc, kết cấu. CNN là nền tảng của hầu hết hệ thống nhận diện khuôn mặt, phân loại ảnh y tế và xe tự lái.
Mạng nơ-ron hồi tiếp (RNN – Recurrent Neural Network)
RNN xử lý dữ liệu tuần tự như văn bản, âm thanh và chuỗi thời gian. Điểm đặc biệt là RNN có bộ nhớ nội tại, cho phép nó nhớ thông tin từ các bước trước đó. Biến thể LSTM (Long Short-Term Memory) và GRU (Gated Recurrent Unit) khắc phục nhược điểm mất mát thông tin dài hạn của RNN gốc.
Mạng đối sinh (GAN – Generative Adversarial Network)
GAN gồm hai mạng đối đầu nhau: Generator tạo dữ liệu giả và Discriminator phân biệt dữ liệu thật-giả. Quá trình huấn luyện cạnh tranh này giúp Generator tạo ra dữ liệu cực kỳ chân thực. GAN được ứng dụng trong tạo ảnh nghệ thuật, chỉnh sửa ảnh, tăng cường dữ liệu huấn luyện.
Mô hình Transformer
Transformer ra mắt năm 2017 đã cách mạng hóa xử lý ngôn ngữ tự nhiên. Kiến trúc này dựa trên cơ chế attention, cho phép mô hình tập trung vào các phần quan trọng của dữ liệu đầu vào. BERT, GPT, T5 đều dựa trên Transformer và đạt kết quả vượt trội trong dịch thuật, tóm tắt văn bản, sinh văn bản.
Quy trình huấn luyện một mô hình Deep Learning
Quy trình huấn luyện Deep Learning bao gồm các bước sau:
Thu thập và tiền xử lý dữ liệu: Dữ liệu phải đủ lớn (hàng nghìn đến hàng triệu mẫu) và được làm sạch, chuẩn hóa.
Xây dựng kiến trúc mạng: Lựa chọn số lớp, số nơ-ron mỗi lớp, hàm kích hoạt (ReLU, Sigmoid, Tanh).
Khởi tạo trọng số: Gán giá trị ngẫu nhiên cho các trọng số kết nối giữa các nơ-ron.
Lan truyền tiến (Forward Propagation): Dữ liệu đi từ lớp đầu vào qua các lớp ẩn đến lớp đầu ra, tính toán đầu ra dự đoán.
Tính toán hàm mất mát (Loss Function): So sánh đầu ra dự đoán với nhãn thực tế, đo lường sai số.
Lan truyền ngược (Backpropagation): Tính gradient của hàm mất mát theo từng trọng số, xác định hướng điều chỉnh.
Cập nhật trọng số: Sử dụng thuật toán tối ưu (SGD, Adam, RMSprop) để giảm thiểu hàm mất mát.
Lặp lại: Quá trình từ bước 4 đến 7 được lặp lại qua nhiều epoch cho đến khi mô hình hội tụ.
Lợi ích của Deep Learning
Tự động trích xuất đặc trưng: Không cần can thiệp thủ công, tiết kiệm thời gian và công sức.
Độ chính xác cao: Vượt trội so với các phương pháp truyền thống trong nhiều tác vụ phức tạp.
Xử lý dữ liệu phi cấu trúc: Làm việc hiệu quả với ảnh, âm thanh, văn bản, video.
Khả năng mở rộng: Hiệu suất cải thiện khi có thêm dữ liệu và tài nguyên tính toán.
Học biểu diễn đa cấp: Từ đặc trưng đơn giản đến phức tạp, từ cục bộ đến toàn cục.
Hạn chế của Deep Learning
Yêu cầu dữ liệu lớn: Cần hàng triệu mẫu để đạt hiệu suất tốt, khó áp dụng khi dữ liệu khan hiếm.
Tài nguyên tính toán khổng lồ: Huấn luyện mô hình lớn cần GPU/TPU mạnh, chi phí điện năng cao.
Thiếu khả năng giải thích: Mô hình hoạt động như “hộp đen”, khó hiểu tại sao đưa ra quyết định cụ thể.
Dễ bị quá khớp (Overfitting): Học thuộc lòng dữ liệu huấn luyện, không tổng quát hóa tốt.
Nhạy cảm với nhiễu: Dữ liệu nhiễu hoặc tấn công đối nghịch có thể làm sai lệch kết quả.
So sánh Deep Learning và Machine Learning truyền thống
Tiêu chí
Machine Learning truyền thống
Deep Learning
Trích xuất đặc trưng
Thủ công, cần chuyên gia
Tự động, học từ dữ liệu thô
Lượng dữ liệu cần
Vài trăm đến vài nghìn mẫu
Hàng chục nghìn đến triệu mẫu
Thời gian huấn luyện
Phút đến vài giờ
Giờ đến vài tuần
Phần cứng yêu cầu
CPU thông thường
GPU/TPU chuyên dụng
Khả năng giải thích
Cao (cây quyết định, hồi quy)
Thấp (hộp đen)
Hiệu suất trên dữ liệu phức tạp
Trung bình
Cao vượt trội
Chi phí triển khai
Thấp
Cao
Ứng dụng thực tế của Deep Learning
Y tế và chăm sóc sức khỏe
Deep Learning được sử dụng để phân tích ảnh X-quang, MRI, CT scan phát hiện khối u, tổn thương. Hệ thống của Google Health đạt độ chính xác 94% trong phát hiện ung thư vú, cao hơn bác sĩ chuyên khoa. Các mô hình còn dự đoán nguy cơ bệnh tim, đột quỵ dựa trên hồ sơ bệnh án điện tử.
Xe tự lái
Các hãng như Tesla, Waymo, Uber sử dụng Deep Learning để xử lý dữ liệu từ camera, radar, LiDAR. Mô hình CNN nhận diện làn đường, biển báo, người đi bộ. RNN dự đoán hành vi của các phương tiện khác. Tesla Autopilot xử lý hơn 1 tỷ dặm dữ liệu lái xe thực tế mỗi ngày.
Xử lý ngôn ngữ tự nhiên
ChatGPT, Google Translate, Siri, Alexa đều dựa trên Deep Learning. Mô hình GPT-4 có 1.76 nghìn tỷ tham số, hiểu và sinh văn bản gần như con người. Google Dịch sử dụng Transformer để dịch 100+ ngôn ngữ với độ chính xác ngày càng cao.
Tài chính và ngân hàng
Deep Learning phát hiện gian lận giao dịch thẻ tín dụng trong thời gian thực. JPMorgan Chase sử dụng mô hình học sâu để phân tích hợp đồng pháp lý, tiết kiệm 360.000 giờ làm việc mỗi năm. Các quỹ đầu tư dùng Deep Learning để dự đoán xu hướng thị trường chứng khoán.
Sản xuất và công nghiệp
Hệ thống thị giác máy tính dựa trên CNN kiểm tra chất lượng sản phẩm trên dây chuyền sản xuất. Siemens sử dụng Deep Learning để dự đoán hỏng hóc thiết bị trước khi xảy ra, giảm thời gian chết máy 30%.
Sai lầm thường gặp khi áp dụng Deep Learning
Thu thập dữ liệu không đủ hoặc mất cân bằng: Dữ liệu ít hoặc lệch lớp dẫn đến mô hình thiên vị, kém chính xác.
Bỏ qua tiền xử lý dữ liệu: Dữ liệu nhiễu, thiếu giá trị, không chuẩn hóa làm giảm hiệu suất nghiêm trọng.
Chọn kiến trúc mạng không phù hợp: Dùng CNN cho dữ liệu chuỗi thời gian hoặc RNN cho ảnh đều sai.
Không kiểm soát quá khớp: Thiếu các kỹ thuật regularization như dropout, early stopping, data augmentation.
Đánh giá mô hình không đúng cách: Chỉ dựa vào accuracy mà bỏ qua precision, recall, F1-score, đặc biệt với dữ liệu mất cân bằng.
Bỏ qua chi phí tính toán: Xây dựng mô hình quá lớn so với tài nguyên phần cứng hiện có.
Lưu ý quan trọng khi triển khai Deep Learning
Bắt đầu với bài toán đơn giản, dùng mô hình nhỏ trước khi mở rộng. Sử dụng transfer learning từ các mô hình tiền huấn luyện như ResNet, BERT để tiết kiệm thời gian và dữ liệu. Luôn chia dữ liệu thành tập huấn luyện, tập validation và tập test theo tỷ lệ 70-15-15 hoặc 80-10-10.
Giám sát quá trình huấn luyện qua các biểu đồ loss và accuracy. Sử dụng early stopping để dừng khi mô hình không cải thiện trên tập validation. Áp dụng kỹ thuật data augmentation để tăng đa dạng dữ liệu. Kiểm tra đạo đức và bias trong dữ liệu trước khi triển khai thực tế.
Câu hỏi thường gặp về Deep Learning
Deep Learning khác gì so với Machine Learning?
Deep Learning là tập con của Machine Learning. Khác biệt chính nằm ở khả năng tự động học đặc trưng từ dữ liệu thô nhờ nhiều lớp ẩn, trong khi Machine Learning truyền thống cần con người trích xuất đặc trưng thủ công.
Cần bao nhiêu dữ liệu để huấn luyện Deep Learning?
Tùy vào độ phức tạp của bài toán. Phân loại ảnh đơn giản cần ít nhất 1.000-5.000 mẫu mỗi lớp. Bài toán phức tạp như nhận diện giọng nói cần hàng trăm nghìn giờ âm thanh. Mô hình ngôn ngữ lớn như GPT cần hàng nghìn tỷ token.
Deep Learning có thể giải thích được không?
Hầu hết mô hình Deep Learning hoạt động như hộp đen, khó giải thích. Tuy nhiên, các kỹ thuật như Grad-CAM, LIME, SHAP giúp hiểu một phần quyết định của mô hình. Lĩnh vực XAI (Explainable AI) đang phát triển để giải quyết vấn đề này.
Học Deep Learning bắt đầu từ đâu?
Nắm vững kiến thức nền tảng về đại số tuyến tính, xác suất thống kê, giải tích. Học Python và các thư viện TensorFlow, PyTorch, Keras. Thực hành qua các khóa học của Andrew Ng (Deep Learning Specialization), fast.ai, và các dự án thực tế trên Kaggle.
Deep Learning có thay thế con người không?
Deep Learning tự động hóa nhiều tác vụ nhưng không thay thế hoàn toàn con người. Công nghệ này hỗ trợ con người trong phân tích dữ liệu, ra quyết định, nhưng vẫn cần sự giám sát, đánh giá đạo đức và sáng tạo từ con người.
Kết luận
Deep Learning là công nghệ nền tảng của cuộc cách mạng trí tuệ nhân tạo hiện nay. Với khả năng học từ dữ liệu lớn, tự động trích xuất đặc trưng và đạt độ chính xác vượt trội, Deep Learning đang thay đổi cách chúng ta sống và làm việc. Từ y tế, tài chính, giao thông đến giải trí, ứng dụng của Deep Learning ngày càng mở rộng.
Tuy nhiên, công nghệ này không phải giải pháp vạn năng. Hạn chế về dữ liệu, tài nguyên tính toán và khả năng giải thích đòi hỏi người dùng phải cân nhắc kỹ lưỡng trước khi áp dụng. Hiểu rõ bản chất, ưu nhược điểm và các lưu ý khi triển khai sẽ giúp khai thác tối đa tiềm năng của Deep Learning, đồng thời tránh những sai lầm tốn kém.